
5.1 Einführung
5.2 Klimadaten
5.3 Hydrologische Daten
5.4 Zeitfunktionen in ArcEGMO zur Bewirtschaftung
5.5 Externe Grundwasserzuflüsse
5.6 Zeitvariante Daten -> relate Zeitfunktionen
5.1 Einführung
Zusätzlich zu den raumbezogenen Eingangsdaten, aus denen das GIS-Datenmodell aufgebaut wird, sind die zeitbezogenen Eingansdaten für die Abbildung der zeitlichen Dynamik über den Modellierungszeitraum wichtig. Vor allem sind die meteorologischen Zeitreihen grundlegende Eingangsgrößen, da die Verfügbarkeit ihrer Zeitreihen, den möglichen Modellierungszeitraum bestimmen.
Allen zeitlichen Informationen muss aber zusätzliche auch ein Raumbezug zugeordnet werden, über den dem Gesamtmodell mitgeteilt wird, welche räumliche Ausprägung bestimmte zeitliche Variabilität haben. So sind die meteorologischen Zeitreihen über die X-Y-Koordinaten ihrer jeweiligen Messstation und die Pegelstandorte z.B. über die Fließgewässer-IDs der jeweiligen Gewässerabschnitte räumlich zuzuordnen. Der Verweis sowohl auf die räumliche als auch auf die zeitliche Datenbasis erfolgt über die Dateien: METEOR.ste, HYD_DATA.ste, BW_DATA.ste, GW_DATA.ste in denen die Namen der entsprechenden Describe – Dateien (zur Definition der Datenstruktur) angegeben werden.
Die zeitbezogenen Eingangsdaten lassen sich wie nach ihrer programmtechnischen Einbindung wie folgt unterteilen:
- Meteorologische Zeitreihen: (Kapitel 5.2)
- Hydrologische Zeitreihen: Pegelzeitreihen, Abflussnachführung, Fremdwasserzufluss (Kapitel 5.3)
- Bewirtschaftung: Einspeisungen, Entnahmen, Überleitungen (Kapitel 5.4)
- Berücksichtung externer Grundwasserzuflüsse (Kapitel 5.5)
- Zeitliche Veränderungen im Raum: Landnutzung, Flurabstände, Veränderungen an Gewässerpunkten (Kapitel 5.6)
Die Zeitreihen sind als ASCII-Tabellen unter dem Verzeichnis Zeit.dat in dem jeweiligen Ordner zu hinterlegen. Dabei gibt es verschiedene Möglichkeiten, den Zeitbezug vorzugeben. Einerseits kann eine getrennte Datumsvorgabe über die Spalten „JAHR“ bis „MINUTE“ vorgenommen werden, worüber die Spalten in den Datentabellen erkannt werden, sofern sie vorliegen. Die Art der zeitlichen Diskretisierung der Daten wird über den Attributnamen der 1. Spalte in der Datentabelle festgelegt (Y für Jahr und Termin in den folgenden Abbildungen). Wenn auf zwei oder mehr zeitbezogenen Spalten zugegriffen werden soll, müssen die kleineren Zeiteinheiten in der Termintabelle immer links stehen, da andernfalls ein größerer Zeitschritt angenommen wird. Andererseits kann aber auch ein achtstelliges Datum „Termin“ eingelesen werden. Hier wird der Termin als eine Zeichenkette eingelesen und erst programmintern in die Bestandteile Tag bis Jahr aufgesplittet. Diese Datenstruktur ist identisch mit dem Exportformat ‘*.TXT’ von Excel. Zu beachten ist, dass die Terminangabe eine geschlossene Zeichenkette darstellt, d.h. statt 1. 1.1980 ist stets 01.01.1980 zu schreiben! Die Zuordnung der Spaltennamen erfolgt in der Strukturdefinitionsdatei …zeit.dat\describe\<XX>_data.sdf. Das sind die Dateien MET_data.sdf, BW_data.sdf, HYD_data.sdf, GW_Data.sdf und relates.sdf.
Für den Zeitbezug der Relate-Tabellen (z-Relate) ist es auch möglich, Mittelwerte, mittlere Monatswerte (M = 1-12) oder einen mittleren Jahresgang in Tagesnummern (TN 0 1-365) vorzugeben. Welche Zeitfunktionen für welche Tabellen verwendet werden können, zeigt die Übersicht in Tabelle 5.1‑1.
Tabelle 5.1‑1: Datenformate, die in den Strukturdefinitionsdateien für die Zeitdaten vorgegeben werden können
| Zeitfunktionen | METEOR | HYD_DATA | BW_DATA | Z_Relate | GW |
| Termin | x | x | x | x | x |
| TerminHM | x | ||||
| JAHR | x | x | x | x | x |
| MONAT | x | x | x | x | x |
| TAG | x | x | x | x | x |
| STUNDE | x | x | x | x | |
| MINUTE | x | x | x | x | |
| MITTLERE_MONATSWERTE | x | x | |||
| MITTELWERT | x | x | |||
| MITTLERER_JAHRESGANG | x | x | x |
Beispiele für verschiedene Zeitvorgaben sind in Abbildung 5.1‑1 bis Abbildung 5.1‑3 dargestellt.

Abbildung 5.1‑1: Zeitvariable Kennwerte – Jahreswerte

Abbildung 5.1‑2: Zeitvariable Kennwerte – Terminwerte
Die einfachste Möglichkeit, einen Zeitverlauf zu definieren, besteht in der Angabe eines Mittelwertes (s. Abbildung 5.1‑3), der dann für jeden Berechnungszeitschritt in der Bilanzierung des jeweiligen Raumelements berücksichtigt wird. In diesem Fall wird kein „Zeitattribut“ wie Termin oder Y angegeben.
Jeweils farbig gekennzeichnet sind in den 3 Abbildungen die Raumbezüge, die eine Zuordnung der Zeitreihen zu den Teileinzugsgebieten bzw. Gewässerabschnitten mit den angegebenen IDs gestatten.

Abbildung 5.1‑3: (Zeitvariable) Kennwerte – Mittelwerte
Im Folgenden wird die Verarbeitung der verschiedenen zeitbezogenen Datenformate im Einzelnen genauer beschrieben.
5.2 Klimadaten
5.2.1 Verwendete Klimagrößen
Zeitbezogene Eingangsgrößen in die Niederschlag-Abfluss-Modellierung sind flächenbezogene Werte
- des Niederschlagsdargebots als flüssiges Wasserangebot an die Boden- bzw. Vegetationsoberfläche und
- der potenziellen Verdunstung.
Liegen diese nicht vor, so ist ihre Ermittlung aus Werten erforderlich, die an Klima- und Niederschlagsstationen, d.h. punktbezogen gemessen werden.
Im Einzelnen sind unter Einbeziehung geeigneter Algorithmen für eine Flächenübertragung der punktuell gemessenen Werte
- der gemessene Niederschlag zum Ausgleich von Windfehlern und Benetzungsverlusten zu korrigieren und für Schneeniederschläge die Schmelzwasserabgaben aus der Schneedecke zu berechnen,
- aus den gemessenen klimatischen Grundgrößen die potenzielle Verdunstung zu ermitteln, da diese nicht direkt gemessen werden kann.
Die potenzielle Verdunstung kann je nach Verfügbarkeit der notwendigen Eingangsdaten (s. Tabelle 5.2‑1) nach verschiedenen Verfahren ermittelt werden.
Die geringsten Anforderungen an die Datenbasis stellt das HAUDE-Verfahren (s. Schrödter 1985).
Die Kombinationsformel nach PENMAN liefert in der Regel exaktere Ergebnisse (s. Schrödter 1985), stellt aber auch wesentlich höhere Anforderungen an die Eingangsdaten.
Auf Grund der geringen Stationsdichte, der damit verbundenen geringen räumlichen Auflösung der benötigten Messdaten und den Unsicherheiten bei einer Flächenübertragung ist die Verwendung des PENMAN-Ansatzes nur für Gebiete zu empfehlen, für die repräsentative Messungen der notwendigen Eingangsdaten vorliegen.
Vor allem für Untersuchungsgebiete in der ehemaligen DDR wird auf Grund umfangreicher Analysen die Nutzung von TURC/IVANOV empfohlen (Dyck 1978, Turc 1961, Wendling 1975, Wendling & Schellin 1986).
Tabelle 5.2‑1: Eingangsgrößen für die Berechnung der pot. Verdunstung
| Eingangsdaten | Symbol | Einheit | Haude | Turc/ Ivanov | Penman | Gras Referenz | |
| Lufttemperatur | T | [mm/DT] | + | * | * | * | * |
| Dampfdruck | e | [hPa] | *[1] | + | * | * | |
| relative Feuchte | RH | [% oder Ant. 1] | *[1] | * | + | + | |
| Windgeschwindigkeit | u | [m/s] | * | * | |||
| Windstärke | Um | [Bf] | + | ||||
| relat. Sonnenscheindauer | n | [h/Tag] bzw. [min/h] | + | + | + | ||
| extraterrestrische Strahlung | Ra | + | + | ||||
| Globalstrahlung | Rs | [mm/DT Wasser-äquivalent] [2] | * | + | * | ||
| Strahlungsbilanz | Rn | * | |||||
| * notwendige bzw. bevorzugte Größe, + Ersatzgröße zur Berechnung der mit * gekennzeichneten Größe | |||||||
[1] Wert der Messung um 14 Uhr
[2] GLOBALSTRAHLUNGSFAKTOR ist in der modul.ste anzugeben (0.03505 für Eingangsdaten in W/m2, 0.004057 für Eingangsdaten in J/cm2)
Zu beachten ist, dass die verschiedenen Berechnungsverfahren i.d.R. Intervallmittelwerte der Eingangsdaten erfordern, lediglich der Haude-Ansatz geht von 14 Uhr Werten aus. Bei der Windgeschwindigkeit ist zu beachten, dass PENMAN und die Grassreferenzverdunstung diese auf 2 m Höhe bezogen erfordern, die Messung aber oft in 10 m Höhe erfolgt und der DWD meist Windgeschwindigkeiten für 10 m Höhe liefert, sofern nicht 2 m Höhenwerte angefordert werden. Hier ist der Anwender gefordert, die Eingangsdaten entsprechend des von ihm gewählten Berechnungsverfahrens bereitzustellen und u.U. notwendige Umrechnungen extern durchzuführen.
Wenn das Steuerwort „WINDGESCHWINDIGKEIT10m“ in der met_data.sdf angegeben ist, erfolgt die Umrechnung/Korrektur von 10 m Höhe auf 2 m Höhe programmintern. Windgeschwindigkeiten, die in 10m Höhe gemessen wurden, werden somit auf das Niveau von 2 m zu korrigiert. Verwendet wurde der Ansatz u2 = u*pow(0.2, 0.13); // DVWK, Gl. 9.26 (S. 85) Annahme: Messung der Windgeschwindigkeit in 10 m Höhe (Standard DWD)Rauhigkeit 0.13 für Gras.
5.2.2 Möglichkeiten der Flächenübertragung
Für die Flächenübertragung können unterschiedliche Verfahren genutzt werden.
- Für die Ermittlung der flächenbezogenen Werte werden mehrere Stationen einbezogen. Dabei werden die Abstände der Stationen zur Fläche berücksichtigt. Die Wichtung kann dabei entweder relativ detailliert erfolgen, indem für mehrere Punkte im Teilgebiet die Gewichtsfaktoren bestimmt, z.B. nach dem Rasterpunktverfahren, und diese dann wieder gemittelt werden. Weniger aufwendig ist die Bestimmung der Gewichtsfaktoren für einen, z.B. den Flächenschwerpunkt.
- Die Gebietsgliederung erfolgt unter Berücksichtigung der zur Verfügung stehenden Stationen, so dass jeder Station genau ein Teilgebiet zugeordnet werden kann.
Die erste Vorgehensweise ist dann angebracht, wenn die Stationsdichte gering ist, aber eine gute Korrelation zwischen den Stationen besteht. Letzteres ist nur gegeben, wenn der Einfluss der Orographie gering ist, also zwischen den Stationen keine signifikanten Höhenzüge liegen (im Tiefland). Im Gebirge ist dies i.d.R. nicht der Fall, weshalb hier das zweite, wesentlich weniger aufwendige Verfahren angebracht ist.
Zu beachten ist außerdem, dass mit keinem dieser Verfahren konvektive und damit örtlich sehr variable Niederschläge angemessen berücksichtigt werden.
Auf Grund der aus hydrologischer Sicht geringen Dichte meteorologischer Stationen ist die Übertragung der Werte vom Punkt auf die Fläche prinzipiell mit Unsicherheiten verbunden.
Im Zuge der Flächenübertragung können auch weitere Zusammenhänge berücksichtigt werden wie
- die Höhenabhängigkeit der Lufttemperatur,
- die Expositions- und Gefälleabhängigkeit der Strahlungsgrößen und
- die Albedoeigenschaften, die in erster Linie durch die Vegetation und die Flächennutzung bestimmt werden.
Die zeitliche Dynamik des Niederschlages prägt entscheidend die Dynamik des Abflussgeschehens. Deshalb wird die verfügbare zeitliche Auflösung des Niederschlages als bestimmend für die zeitliche Auflösung der nachfolgenden Modellrechnungen angesehen.
Allgemein verfügbar sind in der Regel nur Tageswerte. Diese zeitliche Auflösung ist aber für eine adäquate Simulation sehr zeitvariabler hydrologischer Prozesse wie der Infiltration nicht ausreichend. Die zeitliche Verteilung innerhalb dieser zeitlichen Diskretisierung gestattet z.B. nicht die Berücksichtigung von direktabflussauslösenden Spitzenintensitäten des Niederschlages. Für die Modellierung bedeutet dieser Umstand letztlich, dass physikalisch begründete Modellparameter wie die gesättigte hydraulische Leitfähigkeit skaliert werden müssen und damit ihren physikalischen Bezug verlieren.
Die Flächenübertragung erfolgt unter Berücksichtigung der Oberflächenmorphologie. So werden für die Berechnung der potenziellen Verdunstung bei Verwendung der PENMAN-Kombinationsformel das Geländegefälle, die Exposition und die Höhenlage als wichtige Standortcharakteristika berücksichtigt. Die Flächenübertragung wird für jede Einzelfläche in folgenden Arbeitsschritten durchgeführt:
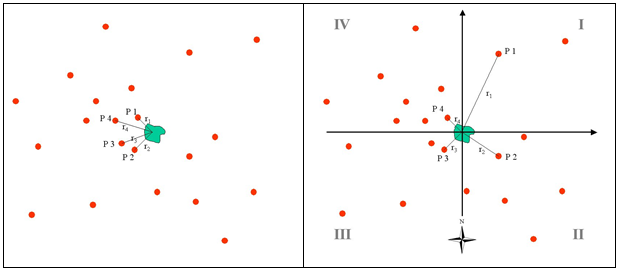
- Ermittlung der zugeordneten Stationen– Entsprechend ihrer Entfernung werden die nächstgelegenen (max.) 4 Stationen für jede Fläche ermittelt. Hierbei kann gewählt werden, ob die Auswahl der Stationen nach dem Quadrantenverfahren erfolgt (s. Abb. rechts), oder ob lediglich die Entfernung berücksichtigt wird und die n nächstliegenden Stationen einbezogen werden. Für die Übertragung des Niederschlages werden Klima- und Niederschlagsstationen genutzt, für die Berechnung der flächenbezogenen potenziellen Verdunstung nur die Klimastationen. Damit wird dem Umstand Rechnung getragen, dass der Niederschlag räumlich variabler ist als andere Klimagrößen und deshalb i.d.R. mehr Niederschlags- als Klimastationen zur Verfügung stehen.
Abbildung 5.2‑1: Auswahl der zugeordneten Stationen – links die 4 nächstliegenden, rechts nach dem „Quadrantenverfahren“ - Ermittlung von Übertragungsfaktoren –Für jede der ausgewählten Stationen werden Faktoren ermittelt, die umgekehrt proportional ihrer Entfernung zur Fläche sind. Verwendet wird dabei die Entfernung im Raum, also unter Berücksichtigung der Höhendifferenz zwischen Station und Fläche.
- Übertragung auf eine fiktive Einzelfläche– Entsprechend dieser Übertragungsfaktoren werden die Stationswerte auf eine fiktive Einzelfläche übertragen, deren Höhenlage dem Mittelwert der Höhenlagen der berücksichtigten Stationen entspricht.
- Übertragung auf die konkrete Einzelfläche– Bei dieser Übertragung werden Korrekturen vorgenommen, die die Höhenabhängigkeit einzelner meteorologischer Größen berücksichtigen. Die Korrektur erfolgt entsprechend der Höhendifferenz zwischen der aktuellen und der fiktiven Einzelfläche und berücksichtigt die mittlere Änderung der entsprechenden Größe pro Höhenmeter. Umfangreiche Regressionsanalysen zeigen eine starke Höhenabhängigkeit des Niederschlages, der Temperatur und des Dampfdruckes, aber nur geringe Höhenabhängigkeiten für weitere Klimagrößen wie z.B. Windgeschwindigkeit. Dazu ist es möglich, während des Programmlaufes die Zeitreihen einer REGRESSIONSANALYSE zu unterziehen oder die Änderungen pro Höhenmeter über die Schlüsselwörter TEMPERATURFAKTOR, NIEDERSCHLAGSFAKTOR und DAMPFDRUCKFAKTOR vorzugeben.
- Ermittlung der Eingangsgrößen für die potenzielle Verdunstung– Entsprechend der geographischen Breite des Untersuchungsgebietes (Angabe über THETA), der Jahreszeit, des Gefälles und der Exposition wird die astronomisch mögliche Sonnenscheindauer und die extraterrestrische Strahlung für die Einzelfläche berechnet. Diese bilden zusammen mit den auf die Einzelfläche bezogenen Werten der Lufttemperatur, des Dampfdrucks, der Windstärke und der aktuellen Sonnenscheindauer die Eingangsgrößen zur Ermittlung der standortbezogenen potenziellen Verdunstung.
{kind=link}
Über ein weiteres Schlüsselwort DATEN_FAKTOR kann eine Umrechnung der Daten gesteuert werden, falls diese wie vielfach üblich in 1/10-Anteilen der benötigten Größenordnung (z.B. in 1/10. mm Niederschlag) angegeben sind.
Über den Eintrag FEHLWERTBELEGUNG wird angegeben, wie Fehlwerte in den Zeitreihen definiert worden sind. Default-Wert ist der Wert –9999.
5.2.3 Datenverwaltung
Die Verwaltung der meteorologischen Zeitreihen und ihre Übertragung auf die zu modellierenden Flächen erfolgt unter Nutzung der Programmkomponente METEOR, während die eigentlichen Modelleingangsgrößen Niederschlagsdargebot und Verdunstung im MET_MODUL (s. Modul MET der Dokumentation) ermittelt werden.
Eine Übersicht über die Wirkungsweise von METEOR gibt Abbildung 5.2‑2.

Abbildung 5.2‑2: Übersicht über die Programmkomponente METEOR
In METEOR wird davon ausgegangen, dass die meteorologischen Daten punkt- bzw. stationsbezogen gewonnen wurden. Angaben zu den Stationen, ihre Lage und die zugeordneten Datentabellen werden in einer Stationstabelle verwaltet.
Zur Steuerung der Aktivitäten von METEOR durch den Nutzer wird die Datei METEOR.STE (s. Abbildung 5.2‑7) genutzt. Diese Steuerdatei besteht aus Anweisungsblöcken
- zur Datenkorrektur,
- zur Flächenübertragung der meteorologischen Daten und
- mit Verweisen auf weitere Dateien mit Beschreibungen der Tabellenstrukturen der Stationstabelle MET_STAT.SDF und der Datentabellen MET_DATA.SDF.
MET_STAT ASCII metstat.tab STATIONSKENNUNG NRM STATIONSTYP TYP DATENZEITINTERVALL DTD RECHTSWERT REF_X HOCHWERT REF_Y HOEHE HOEHE NIEDERSCHLAGSKORREKTUR KOR_PI SCHNEEKORREKTUR KOR_SN
Abbildung 5.2‑3: Datei MET_STAT.SDF- Strukturdefinition der Stationstabellen
Zuerst wird die Datenbasis beschrieben. Diese besteht aus einer Stationstabelle und den eigentlichen Datentabellen, die die Zeitreihen enthalten. Die Struktur dieser Tabellen werden über Definitionstabellen beschrieben, deren Namen über die Schlüsselwörter MET_STAT_DESCRIBE und MET_DAT_DESCRIBE in METEOR.STE angegeben werden. Die Datei MET_STAT.SDF befindet sich im Verzeichnis GIS\DESCRIBE, die Datei MET_DATA.SDF im Verzeichnis ZEIT.DAT\DESCRIBE.
Die Art und Weise, wie Tabellenstrukturen definiert werden, entspricht weitestgehend der schon beschriebenen Methodik bei den Attribut- und Relate-Tabellen der GIS-Schnittstelle.
Der Definitionsblock beginnt mit einem Schlüsselwort als Kennung der Tabelle, gefolgt vom Tabellenformat (ASCII oder INFO) und der Dateibezeichnung. Die folgenden Zeilen beinhalten i.d.R. Angaben zu den Attributen innerhalb der Tabelle bzw. den Spaltenbezeichnern. Nach einem Schlüsselwort zur verbalen Kennzeichnung der Art des Attributes erfolgt die in der konkreten Tabelle verwendete Attributbezeichnung. Datentyp und Speicherformat sind ohne Belang, da programmintern eine sehr variable Zuweisung der Tabellendaten auf Programmvariablen erfolgt.
Abbildung 5.2‑3 zeigt die Datei zur Definition der Stationstabelle. Aus der STATIONSKENNUNG und dem STATIONSTYP wird der Dateiname für die zugeordnete Datentabelle gebildet. Der STATIONSTYP (‘kli’ oder ‘pi’) dient gleichzeitig zur Unterscheidung von Niederschlags- und Klimastationen. Die entsprechenden Datentabellen enthalten entweder nur Niederschlagswerte oder Niederschlagswerte und weitere Klimagrößen. Mit dieser Unterscheidung wird der Tatsache Rechnung getragen, dass der Niederschlag i.d.R. an mehr Stationen gemessen wird als die übrigen klimatologischen Werte. Für die sogenannten Klimastationen wird aber in jedem Fall auch der Niederschlag erwartet.
Das DATENZEITINTERVALL gibt die zeitliche Auflösung der Daten an. In der derzeitigen Programmversion müssen alle Daten aller Stationen die gleiche zeitliche Auflösung besitzen!
RECHTSWERT, HOCHWERT und HOEHE (ü. NN) kennzeichnen die Lage der Station und werden benötigt zur Übertragung der punktbezogenen Stationswerte auf die zu modellierenden Einzelflächen. Da in der Stationstabelle Raumbezüge verwaltet werden, wird die Datei im GIS-Verzeichnis verwaltet.
Beim Einlesen der Klimadaten wird in der arc_egmo.txt (RESULT-Ordner) protokolliert, mit welchen Stammdaten die Station aus der Stationsdatei ausgelesen wurde. Fehlt der Datensatz einer Klimastation, die in der Stationsdatei angegeben ist, so wird darauf in der Protokolldatei hingewiesen.
Für den Fall, dass keine Stationswerte, sondern schon flächenbezogene Werte vorliegen, sind die Koordinaten der Flächenmittelpunkte der zugeordneten Flächen einzutragen. Ist nur eine Reihe pro Datenart im Sinne eines Gebietsmittels gegeben, so können in der Stationsdatei Lageangaben entfallen bzw. mit beliebigen Werten ausgefüllt werden.
Messwerte, so auch Klimadaten sind fehlerbehaftet. Bei der Niederschlagsmessung treten z.B. Messfehler wie Wind- und Benetzungsverluste auf, die systematische Abweichungen der gemessenen Niederschlagsreihen zum „wahren“ Niederschlag verursachen. Üblich ist deshalb eine Korrektur der Messwerte. In ArcEGMO erfolgt die Korrektur des Niederschlages PI gemäß folgender Gleichung
PI = COR * PT
PT stellt den unkorrigierten Niederschlag und COR den Korrekturfaktur dar. Je nachdem, ob der Niederschlag als Schnee oder Regen gefallen ist (Entscheidung in Abhängigkeit von der Lufttemperatur über die Angabe zur GRENZTEMPERATUR), werden unterschiedliche Faktoren für die NIEDERSCHLAGSKORREKTUR und die SCHNEEKORREKTUR zum Ansatz gebracht. Möglich sind z.B. die von Fröhlich (1990) verwendeten Korrekturfaktoren mit COR=1.12 für Regen und COR=1.38 für Schnee. Werden keine Angaben zu den Korrekturfaktoren gemacht, werden diese programmintern auf 1 gesetzt, d.h. es erfolgt keine Korrektur.
NIEDERSCHLAGSKORREKTUR 1.05 /* Korrekturfaktoren zum Ausgleich von Wind- */
SCHNEEKORREKTUR 1.0 /* fehlern und Benetzungsverlusten */
GRENZTEMPERATUR 0.1 /* Grenzwert der Tagesmitteltemperatur, unter */
/* der Schneefall angenommen wird */
GLOBALSTRAHLUNGSKORREKTUR 1 /* Korrektur gemäß Hangneigung und Aspekt */
/* 0 - keine */
/* 1 - trigonometrische Berechnung */
/* 2 - Tabellenfunktion */
Abbildung 5.2‑4: Auszug aus der Datei METEOR.STE- Organisation der Korrektur
Sind stationsbezogene Korrekturfaktoren bekannt, können diese nun direkt zur Korrektur verwendet werden. Ihre Vorgabe erfolgt über zwei Spalten in der Stationstabelle, in die für jede Station die Niederschlags- und die Schneekorrektur einzutragen ist. Die Namen dieser Spalten werden über die Definitionsdatei GIS\DESCRIBE\<met_stat.sdf> dem Programm über die Schlüsselwörter bekannt gemacht. Stationsbezogene Korrekturfaktoren überschreiben die global über die meteor.ste (s. Abbildung 5.2‑7) vorgegebenen Faktoren.
Neben dem Niederschlag kann auch die potenzielle Verdunstung einheitlich (s. met_mod1 in der modul.ste) oder stationsbezogen korrigiert werden.
Wenn in der Met_Stat.sdf die Verdunstungskorrektur aktiviert (das * gelöscht ist) wird, dann kann aus den Inputdaten eine Verdunstungskorrektur erfolgen.
Dies ist für bestimmte Ansätze notwendig, weil z.B. der Turc-Ansatz für eine „kurz gehaltene, ausreichend feuchteversorgte Fläche“ abgeleitet wurde, realen Einzugsgebiete aber auch andere Bodenbedeckungen aufweisen. Für die damalige DDR hatte sich eine Erhöhung der Turc-Verdunstung um 10% als brauchbar erwiesen -> Verdunstungskorrektur wäre 1.1). Eine Korrektur der potenziellen Verdunstung ist auch dann notwendig, wenn das Umfeld der Station nicht repräsentativ für das zu modellierende Gebiet ist.
Für die vorgegebene (d.h. eingelesene) Globalstrahlung kann bei der Übertragung von der Messstation auf die zu modellierende Fläche eine Korrektur gemäß dem Gefälle und der Hangausrichtung dieser Fläche erfolgen unter der Annahme, dass die Messstation auf einer ebenen Fläche steht. Zu beachten ist, dass die Globalstrahlungskorrektur nicht gemeinsam mit dem Quadrantenverfahren ausgeführt werden kann!
Abbildung 5.2‑5 gibt ein Beispiel für eine Stationstabelle, die sich im GIS-Verzeichnis befinden muss, und zwar als eigenes Cover (Angabe über INFO) oder im Falle einer ASCII-Datei im Unterverzeichnis ASCII.PAT. Diese enthält im Beispiel nur einen Eintrag, die Datenbasis besteht also aus Gebietswerten. Die Attribute METSTAT# und METSTAT-ID werden nur für die Darstellung der Stationen im GIS benötigt und wie STATIONSNAME (als verbale Bezeichnung zur besseren Lesbarkeit der Tabelle) vom Programm nicht genutzt.
NRM TYP DTD STATIONSNAME REF_X REF_Y HOEHE KOR_PI KOR_SN test kli 24 'Gebietswerte Test' 3491671 5564387 342 1.1 1.2
Abbildung 5.2‑5: Beispiel einer Stationstabelle
Über das Schlüsselwort MET_DATEN wird für alle Datendateien die Art der Datenbasis – ASCII oder INFO – angegeben. Die Angabe des Tabellen- bzw. Dateinamens entfällt hier, da die Namen, wie schon beschrieben, aus den Einträgen der Stationstabelle gebildet werden. Standardmäßig werden die Datentabellen im Zeitreihen-Verzeichnis gespeichert, und zwar alle Daten einer Station in einer Datendatei.
MET_DATEN ASCII H:\Alle_Zeitreihen Termin termin /* durch "." getrennte Datumszeichenkette */ TAG d MONAT m JAHR y STUNDE h MINUTE min LUFTTEMPERATUR Tm [°C ] DAMPFDRUCK e [hPa ] RELATIVE_FEUCHTE rf [%] oder [Anteile von 1.] WINDSTAERKE Um [Bf ] SONNENSCHEINDAUER n [h/d ] POTENTIELLE_VERDUNSTUNG EP [mm/d] NIEDERSCHLAG PT [mm/d]
Abbildung 5.2‑6: Datei MET_DATA.SDF – Strukturdefinition der Datentabellen
Es ist aber auch möglich, die Zeitreihendaten in projektunabhängigen Verzeichnissen zu verwalten, beispielsweise um Redundanzen zu vermeiden. In diesem Fall wird neben dem Datenformat (ASCII) auch der Pfad zu diesen Datendateien angegeben. Zu beachten ist hierbei, dass der komplette Pfad angegeben wird und dass die Pfadangabe mit einem Slash („\“) abgeschlossen wird.
Die eigentlichen meteorologischen Daten werden über die Einträge LUFTTEMPERATUR bis NIEDERSCHLAG als die Spaltenbezeichner für die Datenarten definiert. Sofern diese Spalten dann in den Datentabellen vorhanden sind, werden die dazu gehörenden Daten eingelesen und verarbeitet. Tabelle 5.2‑2 zeigt die Datenarten, die derzeit verarbeitet werden, Tabelle 5.2‑1 die Zuordnung dieser Daten zu den derzeit integrierten Verdunstungsansätzen.
Wenn in der einzulesenden Datenbasis allerdings eine bestimmte Datenart nicht gegeben ist, so ist diese in der Datei zeit.dat\describe\met_data.sdf auch nicht anzugeben bzw. sie ist auszukommentieren. Andernfalls wird diese Datenart zuerst mit Fehlwerten belegt und anschließend wird versucht, diese Fehlwerte über die Einbeziehung von Nachbarstationen zu eliminieren. Sind auch diese mit Fehlwerten belegt, was hier der Fall wäre, werden Default-Werte gesetzt, was zu unrealistischen Ergebnissen führen wird.
Neben der bisher beschriebenen Verwaltung der meteorologischen Eingangsdaten und der Ermittlung abgeleiteter Größen wie der potenziellen Verdunstung ist eine weitere wichtige Aufgabe der Programmkomponente METEOR die Übertragung der Klimawerte auf die Modellierungseinheiten. Dies können Elementarflächen, Kaskadensegmente, Teileinzugsgebiete oder das Gesamtgebiet sein. Die Festlegung erfolgte innerhalb der Steuerdatei ARC_EGMO.STE.
Tabelle 5.2‑2: Mögliche Eingangszeitreihen im Modellteil METEOR
| Datenart | Einheit | Default | Bemerkung |
| Lufttemperatur | °C | 8 | |
| Dampfdruck | hPa | 10 | |
| relative Feuchte | % oder Anteile von 1. | Alternativ zum Dampfdruck | |
| Windstärke | Bf | 0,5 | nur für Penman |
| Sonnenscheindauer | h/d | 0 | |
| pot. Verdunstung | mm/DT | 0 | |
| Niederschlag | mm/DT | 0 |
Bei einer Übertragung auf das Gebiet werden in Abhängigkeit von der Anzahl der zur Verfügung stehenden Zeitreihen (s. Stationstabelle – Abbildung 5.2‑5) Gebietswerte gebildet, was mit Informationsverlusten verbunden ist und nur zu Testzwecken eingesetzt werden sollte. Ist nur eine Zeitreihe gegeben, so wird diese als gebietsbezogen interpretiert. Eine Übertragung auf kleinere Einheiten bringt keinen Informationsgewinn und wird deshalb vom Programm nicht akzeptiert. Lediglich eine höhenabhängige Modifikation des Gebietsniederschlages wird unterstützt, sofern ein NIEDERSCHLAGSFAKTOR (s. Abbildung 5.2‑7) zur Berücksichtigung der Änderung der mittleren Niederschlagssumme pro Höhenmeter angegeben werden kann.
THETA 53.5 /*geographische Breite des Untersuchungsgebietes*/
FLAECHENUEBERTRAGUNG 0 /* Quadrantenverfahren */
/* n (1,2,3) -Stationenverfahren
REGESSIONSANALYSE NEIN /* JA: Ermittlung und Anzeige der nach- */
/* folgenden 3 Faktoren, */
/* NEIN: nachfolgende 3 Faktoren gelten */
GLOBALSTRAHLUNGSKORREKTUR 1 /* Korrektur gemäß Hangneigung und Aspekt */
/* 0 - keine, */
/* 1 - trigonometrische Berechnung, */
/* 2 - Tabellenfunktion */
DATEN_FAKTOR 0.1 /* Faktor, falls Daten z.B. in 1/10 mm gegeben */
TEMPERATURFAKTOR 0. /* Temperaturaenderung pro Hoehenmeter */
NIEDERSCHLAGSFAKTOR 0.001754 /* Aenderung der mittleren Niederschlagstages- */
/* Summe pro Hoehenmeter */
DAMPFDRUCKFAKTOR 0. /* Dampfdruckaenderung pro Hoehenmeter */
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
NIEDERSCHLAGSKORREKTUR 1.1 /* Korrekturfaktoren zum Ausgleich von Wind- */
SCHNEEKORREKTUR 1.25 /* fehlern und Benetzungsverlusten */
GRENZTEMPERATUR 0.1 /* Grenzwert der Tagesmitteltemperatur, unter */
/* der Schneefall angenommen wird */
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
LUECKEN_FUELLEN
*DATENTABELLEN_AUSGEBEN
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
MET_STAT_DESCRIBE met_stat
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
MET_DAT_DESCRIBE met_data
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
FEHLWERTBELEGUNG Fehlwert /* Kennzeichnung nichtgemessener Daten */
/* z.B. Geraeteausfall */
Abbildung 5.2‑7: Steuerdatei METEOR.STE – Optionen zur Flächenübertragung
5.2.4 Verarbeitung von Klimareihen mit zeitlichen Lücken
Für die Verarbeitung von Zeitreihen in ArcEGMO war bisher eine grundlegende Bedingung, dass diese keine zeitlichen Lücken aufweisen. Das bedeutet, dass eventuelle Fehlzeiträume über Fehlwerte abgebildet werden mussten. Wurde dies nicht beachtet, kam es zu Fehlern in der zeitlichen Zuordnung der Niederschläge mit gravierenden Auswirkungen auf die Modellierungsergebnisse.
Für die Verarbeitung solcher lückigen Zeitreihen wurde eine Einleseroutine in ArcEGMO integriert, die über das Schlüsselwort LUECKEN_FUELLEN in der Steuerdatei ARC_EGMO\meteor.ste aktiviert (siehe Abbildung 5.2‑9) werden kann.
Werden von dieser Routine lückenbehaftete Zeitreihen gefunden, erfolgt (bei aktiviertem Testdruck der meteor.ste) die Ausgabe eines Warnhinweises „Reihe <nr> weist ab <Datum> eine Luecke auf !!!“ in der Protokolldatei arc_egmo.txt und die Lücke wird mit dem definierten Fehlwert gefüllt.
Für die Kontrolle der im Programm ArcEGMO integrierten Routinen zum Füllen von Datenlücken ist es nun möglich, die verarbeiteten Niederschlagsreihen komplett in eine Datei ZEIT.DATpi.txt auszugeben. Diese Option wird über das Schlüsselwort DATENTABELLEN_AUSGEBEN in der Steuerdatei ARC_EGMO\meteor.ste aktiviert. Die dabei erzeugte Datei kann maximal 255 Zeitreihen enthalten. Werden mehr Zeitreihen für die Modellierung verwendet, werden nur die ersten 255 Reihen ausgegeben. Weitere Reihen können über eine eventuelle Umsortierung der Stationen in der Stationstabelle ausgegeben werden.
termin cl_3342 46645 47030 01.01.81 1.50 2.30 0.00 02.01.81 11.30 10.20 8.10 03.01.81 6.10 6.90 6.70 ..
Abbildung 5.2‑8: Auszug aus einer Datei ZEIT.DATpi.txt
Bisher wurden Lücken in den meteorologischen Zeitreihen nur im kleinsten gemeinsamen Zeitraum aller vorhandenen Zeitreihen gefüllt und durch Messwerte benachbarter Stationen ergänzt. Somit mussten die Zeitreihen gegebenenfalls extern durch Reihenverlängerung mit Fehlwerten (-9999) auf einen gleichen gemeinsamen Berechnungszeitraum gebracht werden.
Jetzt können auch Lücken über einen beliebig langen Zeitraum außerhalb des kleinsten gemeinsamen Zeitraums gefüllt werden. Ein Füllen der Lücken bedeutet, dass finden tatsächlicher Lücken in Zeitreihen anhand eines fehlenden Datums und das Ersetzen dieser Datenlücke durch eine Fehlkennung (-9999). Bei dem neuen automatischen Füllen der Lücken wird vom Bearbeiter eine große Aufmerksamkeit und Kontrolle des gewählten Zeitraums gefordert, damit dann der für die Berechnung verwendete Zeitraum wirklich realistisch ist und durch ausreichend vorhandene Messwerte repräsentiert wird.
++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++ LUECKEN_FUELLEN DATENTABELLEN_AUSGEBEN ++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
Abbildung 5.2‑9: Auszug aus meteor.ste
In der arc_egmo.ste wird über den Berechnungszeitraum der gewünschte Datenzeitraum, also der Zeitraum, für den die „aufgefüllten“ Stationsreihen erzeugt werden sollen, eingestellt. Alle meteorologischen Zeitreihen, die später beginnen oder früher enden, müssen durch eine Anfangs- und Endfehlkennung gekennzeichnet sein (siehe Beispiel Abbildung 5.2‑10). Alle Zeitreihen müssen durch die Belegung einer Anfangs- und Endfehlkennung gleich lang sein. Der 2. Tag der meteorologischen Zeitreihe muss ebenfalls mit einer Fehlkennung gekennzeichnet sein, sonst wird der eingestellte Zeitschritt, bei Tageszeitreihen DTD 24, nicht erkannt. Die Größe der Lücke bis zum ersten Messwert spielt dann keine Rolle mehr.
ta mo jahr nied 01 01 1950 -9999 02 01 1950 -9999 01 01 1957 4.8 … … 31 12 2005 -9999
Abbildung 5.2‑10: Auszug Niederschlagsdatei
Für die Klimagrößen
- e (Sättigungsdefizit)
- Glob (Globalstrahlung)
- Lt (Lufttemperatur)
- Pi (Niederschlag)
- RF (relative Luftfeuchte)
werden im Verzeichnis Zeit.Dat Zeitreihen mit der Lückenkennzeichnung (als Fehlkennung mit –9999) erstellt (z.B. pi_luecken.txt). Hier lässt sich in einer späteren Kontrolle, anhand der Fehlkennung der ausgefallenen Stationen leicht der für die repräsentativen Berechnungen maximal mögliche Zeitraum ermitteln.
Im zweiten Schnitt des „Lückenfüllens“ werden die Lücken (Fehlkennung z.B. –9999), beim Ausfall von nur einigen Stationen durch die Werte der benachbarten Stationen höhen- und entfernungsgewichtet mittels dem Quadratenverfahren ergänzt. Liegen an allen Stationen keine Messwerte vor, wird hier die Lücke mit einem Default-Wert ergänzt.
Folgende Default-Werte werden verwendet:
Niederschlag 0. [mm/DT]
Pot. Verdunstung 0. [mm/DT]
mittl. Lufttemperatur 8 [°C]
Sättigungsdefizit 5.8 [hPa]
Sonnenscheindauer 0. [h]
Windgeschwindigkeit 0.5 [m/s]
Globalstrahlung 500 [J/cm**2]
Diese Ergänzungen werden zum einem gemeinsam, d.h. alle Stationen in eine Datei (z.B. pi_ergaenzt.txt) ausgegeben. Zusätzlich werden alle Einzeldateien der Niederschlags- und Klimastationen mit den Ergänzungen als neue Dateien mit der vorangehenden Kennung „st_“ (z.B. st_3189.kli) ausgegeben. Somit ist es dem Bearbeiter, je nach Aufgabenstellung, möglich diese neu erstellen Dateien als neue meteorologische Zeitreihen einzulesen. Nach der Ausgabe der neuen Zeitreihen wird ArcEGMO automatisch beendet. Es findet also keine Berechnung statt. Damit werden Automatismen ohne ausreichende Datenprüfung verhindert. Um die Berechnung mit den ergänzten Zeitreihen zu starten muss „LUECKEN_FUELLEN“ wieder deaktiviert werden. Die Zeiträume, an denen an allen Stationen keine Messwerte vorliegen, müssen vom Bearbeiter beachtet werden und der maximal mögliche Berechnungszeitraum für die Modellrechnungen selbständig gewählt werden. Im Projekt „Extreme Hochwasserabflüsse und Kumulschadenspotenziale im Bodegebiet“ hat sich die Anwendung des „Lückenschließens“ bewährt. Hier lagen sehr unterschiedlich lange Zeitreihen vor und es war notwendig, einen großen gemeinsamen Zeitraum zu haben, auch wenn der nicht repräsentativ ist. Über die Auswertung der Lückendateien z.B. pi_luecken.txt konnten dann schnell Zeiträume gefunden werden, die ausreichend durch Messwerte gekennzeichnet sind. Im diesem Projekt wurden dann nur einzelne Hochwasser mit ausreichend vorhanden meteorologischen Zeitreihen gerechnet.
Folgende Abbildung zeigt Tagesniederschläge im Einzugsgebiet der Bode. Grün markierte Werte sind gemessene Werte. Für die zwei Stationen Hasselfelde und Quedlinburg liegen an dem Tag keine Messwerte vor. Hier werden die Niederschlagswerte (rot dargestellt) anhand des höhen- und entfernungsgewichteten Quadratenverfahrens ermittelt.

Abbildung 5.2‑11: Ermittlung der Niederschlagswerte für ausgefallene Stationen
Bei Klimastationen, die komplett ohne Niederschlagswerte vorliegen, kann ebenfalls das Lückenfüllen angewendet werden. Prinzipiell muss für jede Klimastation der Niederschlag vorliegen. Das heißt, er wird bei Einlesen einer Klimastation erwartet und die Spalte „nied“ muss vorhanden sein, sowie das Steuerwort NIEDERSCHLAG in der met_data.sdf aktiviert sein. Der Niederschlag kann aber durch die Aktivierung von „LUECKEN_FUELLEN“ in der meteor.ste automatisch von den benachbarten Stationen übertragen werden. Dokumentation dazu, siehe oben (à Füllen von Lücken in Meteorologischen Zeitreihen). Beim Lückenfüllen muss, wenn kein Niederschlag vorhanden ist, die Spalte für den Niederschlag komplett mit –9999 ausgefüllt werden.
TIPP: Bei einigen Klimagrößen liegen häufiger Fehlwerte vor (z.B. bei Windgeschwindigkeit). Beim Lückenfüllen dieser Fehlwerte durch Interpolation der Werte von Nachbarstationen macht es Sinn die Anzahl der zur Verfügung stehenden Klimastationen als Anzahl für die Flächenübertragung einbezogenen Stationen zu verwenden. Damit ist sichergestellt, dass die Fehlwerte auch dann ersetzt werden, wenn zu einem Zeitpunkt nur Messwerte für eine Station vorliegen.
5.2.5 Verarbeitung „gemischter“ Klimadaten
Um die Verarbeitung von Klimadatendateien, die teils die Globalstrahlung und teils die Sonnenscheindauer enthalten, zu vereinfachen, wurde eine Funktion integriert, mit der programmintern die Globalstrahlung aus der Sonnenscheindauer für die Stationen berechnet wird, für die keine Strahlungsdaten vorliegen. Die Nutzung dieser Option wird nur empfohlen, wenn die Strahlung für die meisten Stationen vorliegt und nur wenige Reihen um die intern berechnete Strahlung zu ergänzen sind. Folgende Einstellungen sind vorzunehmen:
- In der meteor.ste muss die Option „Luecken_Fuellen“ (s. Kapitel 5.2.4) aktiviert sein, weil nur so schon während des Einlesen für die Klimadaten ein Zeitbezug bereitsteht, der für die Berechnung der astronomisch möglichen Sonnenscheindauer erforderlich ist.
- In der modul.ste muss im Block met_mod1 die Berechnung der Globalstrahlung deaktiviert sein und die nachfolgend angegebenen Steuerworte aktiviert sein.
MET_MOD1
GLOBALSTRAHLUNGSANSATZ 0 /* 0 Gegeben
GLOBALSTRAHLUNGSFAKTOR 0.004057 /* 0., wenn Globalstrahlung berechnet wird, */
/* ansonsten Umrechnungsfaktor der gegebenen */
/* Globalstrahlung in [mm/DT Wasseraquivalent]*/
FAKTOR_A 0.18 /* Faktor im Ansatz zur Berechnung der Global- */
FAKTOR_B 0.62 /* strahlung aus der relativen Sonnenschein- */
/* dauer ra = rex * ( a + b * n_rel) */
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
3. In der met_data.sdf muss gewährleistet sein, dass die Sonnenscheindauer und die Globalstrahlung eingelesen werden können.
SONNENSCHEINDAUER sonn [h/d ] GLOBALSTRAHLUNG stra [j/cm²]
5.2.6 Aggregieren und Disaggregieren von met. Zeitreihen
ArcEGMO erfordert für die Simulation äquidistante Klimadaten mit einer einheitlichen zeitlichen Auflösung für alle Stationsreihen.
Insbesondere für Hochwassersimulationen ist diese Einschränkung oft hinderlich, weil der zur Verfügung stehende Datenbestand meist inhomogen ist. In der Regel liegen eine Reihe von Tageswertreihen und wesentlich weniger hoch aufgelöste Daten vor.
Um eine gewisse Homogenisierung des Datenbestandes zu unterstützen, wurden in ArcEGMO Routinen integriert, die zeitliche Aggregierung und Disaggregierung meteorologischer Zeitreihen unterstützen.
Da derartige Daten“manipulationen“ (insbesondere die Disaggregierung) sehr unsicher sind, wird wie nach dem Lückenfüllen das Programm nach Erzeugung der neuen Zeitreihen automatisch beendet, so dass der Nutzer die Möglichkeit hat (bzw. gezwungen ist), die Daten zu kontrollieren.
Für die Aktivierung dieses Programm-Modus ist in der meteor.ste über das Steuerwort die angestrebte Diskretisierung anzugeben.
ZEITSCHRITTWEITE 60. /* in Minuten */
Abbildung 5.2‑12: Auszug aus meteor.ste
Wenn eine ZEITSCHRITTWEITE angegeben ist und nur dann werden unterschiedlich diskretisierte Zeitreihen beim Einlesen akzeptiert, deren (gegebene) zeitliche Diskretisierung in der Stationsdatei vorzugeben ist.
Für die Bearbeitung der Zeitreihen wird zuerst getestet, ob die zeitliche Diskretisierung kleiner oder größer als die angestrebte Diskretisierung ist.
Ist sie kleiner, erfolgt eine Aggregierung
· für die Größen pi, ep und ra durch Summation,
· für die Größen tmit, tbod e und u durch Mittelbildung und
· für die Größen tmin und tmax durch eine Minimum- bzw. Maximumsuche.
Ist die Zeitschrittweite 1440, d.h. es sollen Tageswerte erzeugt werden, erfolgt eine Aggregierung bis zum nächsten Tag um 7:30 Uhr, dem Ablesetermin der meteorologischen Beobachtungen beim DWD. Dies ist bei der Festlegung des Endzeitpunktes für die Datenauswertung und bei der Datenbereitstellung zu berücksichtigen.
Ist die zeitliche Diskretisierung der Stationsreihe größer als die angestrebte Diskretisierung erfolgt eine Disaggregierung. Dazu wird die nächst gelegene Niederschlagsstation gesucht, bei Klimastationen zusätzlich die nächstgelegene Klimastation, die Daten in der angestrebten zeitlichen Diskretisierung aufweist.
Die zeitliche Verteilung der Daten dieser Bezugsstationen werden auf die zu disaggregierenden Daten aufgeprägt, d.h. es wird der gleiche zeitliche Verlauf innerhalb des gröberen Zeitschrittes wie an der Bezugsstation angenommen, allerdings normiert auf den Wert der Basisstation. Wurde an der Basisstation ein Niederschlag registriert, während an der Bezugsstation kein Niederschlag gefallen ist, wird angenommen, dass dieser Niederschlag konvektiver Natur war. Konvektive Niederschläge haben in der Regel eine sehr geringe räumliche Ausdehnung, meist hohe Intensitäten und sind häufig in den späten Nachmittagsstunden. Deshalb wird (mangels besseren Wissens) diesem Niederschlag eine Dauer von einer Stunde, beginnend um 17 Uhr zugewiesen. Derzeit können nur der Niederschlag und die potenzielle Verdunstung disaggregiert werden. Die potenzielle Verdunstung ist vorher im vorhandenen Zeitschritt zu berechnen und an die entsprechenden Klimastationen anzufügen. Bei der Disaggregierung wird die potenzielle Verdunstung in gleiche Teile über den gewünschten Zeitschritt verteilt (z.B. bei der Disaggregierung von Tageswerten in Stundenwerten durch 24 dividiert).
Zu beachten ist, dass entweder eine Aggregierung oder eine Disaggregierung durchgeführt werden kann. Es dürfen in Klimastationstabelle nur max. 2 unterschiedliche Datenzeitintervalle (DTD) angegeben werden.
5.2.7 Nutzung von Klimadatenbanken
Zunehmend können Klimadaten auch über Datenbanken zur Verfügung gestellt werden, aus denen dann die einzelnen Klimaelemente über ihren Raum- und Zeitbezug abgefragt werden können. Beispiele für solche Datenbanken sind HYRAS der BfG bzw. des DWD, aber auch RAKLIDA.
Der Zugriff auf Datenbanken wird aktiviert, wenn in der arc_egmo.ste das Schlüsselwort DATENBANKANBINDUNG, der Name der Datenbank und die Datendatei inklusive Pfad gefunden wird.
DATENBANKANBINDUNG RAKLIDA c:\Sachsenklimdatenraklida.hdf5
ArcEGMO stellt dann eine Verbindung zu der angegebenen Datenbank her und liest Zeitschritt für Zeitschritt die Daten ein und ordnet sie den für die Klimamodellierung gewählten Raumbezügen (EFL, HYD, TG …) zu. Die Nutzung der internen Methoden zur Flächenübertragung der Klimadaten entfällt.
5.2.8 Massendatenformat und Rasterdatenformat
Das bisherige Datenformat war auf die Verarbeitung einer überschaubaren Anzahl von Stationsreihen (max. 300 bis 400 Stationen) ausgerichtet. Es wurde davon ausgegangen, dass sämtliche Daten (komplette Zeitreihen aller Stationen) während der Modellinitialisierung in den Hauptspeicher geladen werden können.
Für die Verarbeitung sehr großer Datenmengen (räumlich hoch aufgelöste, gridbasierte Klimadaten oder sehr lange Zeitreihen) wird als Alternative zum bisherigen Datenformat das im Folgenden beschriebene Eingabeformat unterstützt.
Jeder Datentyp wird in genau einer Datei abgebildet, in der spaltenweise die Daten eines Raumbezuges (Stations- oder Rasterbezug) stehen. In jeweils einer Zeile stehen alle Werte eines Datentyps für einen Termin. Die Angabe des Termins sollte als eine Zeichenkette erfolgen, und zwar wie in Excel üblich in der Reihenfolge Tag.Monat.Jahr, getrennt durch „.“ Sofern die zeitliche Diskretisierung feiner als ein Tag ist, wäre der Stunden und Minutenwert analog dem folgenden Beispiel zu ergänzen und die gesamte Terminangabe in Hochkommata einzuschließen, um damit wieder die Auswertung der Terminangabe als eine Zeichenkette zu ermöglichen.
termin 3978 3988 3182 2344 3972 3191 … '01.07.2002 00:00' 1.10 0.00 10.7 5.60 7.10 2.90 … '01.07.2002 01:00' 0.10 0.00 0.7 0.60 0.10 0.30 … …
In der ersten Zeile stehen die Spaltenbezeichner (termin und <STATIONSKENNUNG>), wobei die <STATIONSKENNUNG> analog zum bisherigen Datenformat (s. Dokumentation Teil1, Tab. 5.2), allerdings hier zwingend als numerischer Wert zu verwenden ist.
In den nachfolgenden Zeilen genau der Termin und Wert für einen Zeitschritt. Als Spaltentrenner sollte vorzugsweise der Tabulator verwendet werden.
Die Reihen müssen kontinuierlich und äquidistant sein, d.h. Lücken und Fehlwerte werden beim Einlesen nicht gefüllt.
Bei Verwendung dieses Datenformats sind mindestens 2 Dateien, eine für den Niederschlag und eine für die potenzielle Verdunstung bereitzustellen. Alternativ zur Verdunstungsdatei können auch die Eingangsgrößen für die Verdunstungsberechnung in separaten Dateien zur Verfügung gestellt werden, d.h. Dateien für die Lufttemperatur, die Globalstrahlung/Sonnenscheindauer, die relative Luftfeuchte und u.U. die Windgeschwindigkeit/-stärke.
Die Dateien werden über ihren Dateitypen unterschieden, der den in der met_data-sdf angegebenen Datentypen entsprechen. Der Dateiname ist für alle Datentypen (alle Datendateien) gleich und wird in der met_data.sdf gemeinsam mit dem Tabellenformat {ASCII|DBASE} und dem Pfad zu den Daten angegeben. Im folgenden Beispiel hieße die Datei mit den Niederschlägen met_ras1.pt, die mit der potenziellen Verdunstung met_ras1.ep.
Die Verdunstungswerte bzw. die Eingangsgrößen zu ihrer Ermittlung können in einer anderen Raumauflösung vorliegen als die Niederschlagsdaten.
MET_DATEN ASCII H:\Mulde\zeit.dat\met_data\met_ras1 … WINDSTAERKE Um [Bf ] SONNENSCHEINDAUER n [h/d ] POTENTIELLE_VERDUNSTUNG EP [mm/d] NIEDERSCHLAG PT [mm/d]
Der Raumbezug wird hier wie bisher über die <met_stat.tab> (s. Dokumentation, Kap. 5.1.3) hergestellt, die als Schlüsselattribut die <STATIONSKENNUNG> enthalten muss.
Die <met_stat.tab> kann z.B. eine Attributtabelle eines Rasters sein, für die die meteorologischen Daten bereitgestellt werden. Die Raster-ID wäre dann die <STATIONSKENNUNG>. Die Flächenübertragung der rasterbezogenen Daten erfolgt ebenfalls analog der bisherigen Verfahrensweise über ein modifiziertes inverses Distanzverfahren (IDV), wobei die Entfernungen zwischen dem Schwerpunkt der zu modellierenden Fläche und den Schwerpunkten der umgebenden Rasterzellen ausgewertet werden. Sofern die meteorologischen Daten für Gitterpunkte erzeugt wurden, wären die Koordinaten der Gitterpunkte zu verwenden. Sofern die Rasterzellen hinreichend klein bezogen auf die Modellierungsflächen sind, wäre das IDV so anzuwenden, dass nur die nächstliegende Rasterzelle verwendet wird.
Aktiviert wird das Einlesen dieses Formats über die Angabe DATENFORMAT 1 in der Steuerdatei meteor.ste.
Beim Einlesen der Dateien wird geprüft, ob alle Daten über den Simulationszeitraum komplett eingelesen werden können. Wenn nicht, erfolgt die Abarbeitung Zeitschritt für Zeitschritt, d.h. die Daten werden zeilenweise gelesen und immer nur der aktuelle Zeitschritt im Hauptspeicher gehalten.
Bei der praktischen Arbeit mit dem Massendatenformat ergaben sich teilweise sehr lange Zeiten für das Einlesen der Daten insbesondere dann, wenn mit einem sehr feinmaschigen Raster gearbeitet werden soll. Um diese Verarbeitungszeiten zu verkürzen, bietet es sich unter Umständen an, die sonst sehr aufwendigen Datentestungen zu reduzieren. Voraussetzung dafür ist, dass die Massendaten in einer einheitlichen Struktur (alle Eingangsdaten in gleicher Struktur, d.h. gleiche Anzahl Stationen bzw. Rasterzellen und gleiche zeitliche Auflösung und Zeitperiode) und sortiert vorliegen. Sortiert bedeutet, dass die Spaltenreihenfolge in der Datentabelle identisch mit der Stationsreihenfolge in der Stationstabelle ist und dass die Anzahl der Stationen in beiden Tabellen identisch ist.
Für diesen Spezialfall wurde eine zusätzliche, vereinfachte Einlesemöglichkeit für im Massendatenformat vorliegende Daten geschaffen. Diese kann durch den Eintrag 2 für das DATENFORMAT in der Steuerdatei meteor.ste aktiviert werden:
DATENFORMAT 2 /* 0 - Stationsbezogene Daten (default, d.h. so wie bisher */
/* 1 - Massendatenformat */
/* 2 – Rasterdatenformat */
Als TYP in der Stationstabelle muss beim Rasterdatenformat „m“ angegeben werden.
5.2.9 HYRAS-Datenformat
Die vom AG gelieferten meteorologischen Eingangsdaten (Tagesniederschläge, Lufttemperatur, Globalstrahlung, relative Luftfeuchte) im Format der HYRAS-Rasterdaten[3] (ASCII-Format, 5 km Raster)
- als Referenzdaten für den Zeitraum 1951-2006 und
- zur Charakterisierung möglicher Klimaentwicklungen über drei Projektionen für den Zeitraum 1951-2100
entsprechen weitgehend dem in ArcEGMO integrierten „Massendatenformat“. Dieses für sehr große Datenmengen konzipierte Eingabeformat besteht aus einer GIS-Datei und je einer Zeitreihendatei für jede meteorologische Variable.
Über die GIS-Datei (s. Tabelle 4‑1) wird die Verknüpfung zwischen den Rastern und den meteorologischen Daten hergestellt (Attribut CELLCODE) und topografische Informationen zu den Rastern (Koordinaten des Rastermittelpunktes, mittlere Rasterhöhe ELV_SRTM) für die räumliche Übertragung der rasterbezogenen Daten auf die Modellgeometrien der Abflussbildungsmodellierung (Teilgebiete, Hydrotope oder Elementarflächen) bereitgestellt.
Tabelle 5.2‑3: Auszug aus der GIS-Datei im Massendatenformat von ArcEGMO
| X_GEO | Y_GEO | X_BRB | Y_BRB | ELV_SRTM | CELLCODE | DTD | TYP |
| 12.252 | 52.561 | 3313714 | 5826939 | 40.9 | 4147528625 | 24 | m |
| 12.877 | 52.780 | 3356788 | 5849919 | 32.5 | 4187528875 | 24 | m |
| 12.981 | 53.196 | 3365137 | 5896017 | 70.5 | 4192529325 | 24 | m |
| … |
Tabelle 5.2‑4: Auszug aus einer Datendatei im Massendatenformat von ArcEGMO
yy mm dd hh 4147528625 4227529825 4192529325 … 1951 01 01 24 0.06 0.33 0.29 0.18 1951 01 02 24 0.0 0.0 0.0 0.0 1951 01 03 24 0.0 0.0 0.0 0.0 …
In den bereitgestellten Originaldateien im HYRAS-Format waren in den Zeilen 1 bis 4 die
- Bezeichnung der Variablen (Precipitation, Temperature,…)
- mittlere Höhe der Rasterzelle
- X-Koordinate des Rastermittelpunktes (Lambert-Projektion, Datum ETRS89)
- Y-Koordinate des Rastermittelpunktes (Lambert-Projektion, Datum ETRS89)
angegeben. Diese Zeilen wurden gelöscht.
Um zum Massendatenformat von ArcEGMO kompatibel zu sein, war es nun noch erforderlich, die Datendateien mit einem einheitlichen Namen zu versehen, während über den Dateityp die Art der meteorologischen Daten vorzugeben war.
Tabelle 5.2‑5: Bezeichnungen der Datendateien im Massendatenformat von ArcEGMO
| Datei | Datenart | Einheit |
| KLIWAS_05km_d_Brb_Spree_1951_2006.N | Unkorrigierter Niederschlag | [mm/Tag] |
| KLIWAS_05km_d_Brb_Spree_1951_2006.RG | Globalstrahlung | [J/cm2] |
| KLIWAS_05km_d_Brb_Spree_1951_2006.RH | Relativer Luftfeuchte | [%] |
| KLIWAS_05km_d_Brb_Spree_1951_2006.T | Lufttemperatur | [°C] |
HYRASmix, um REGNIE-Daten in Kombination mit klassischen stationsbezogenen Klimadaten nutzen zu können
Auszug aus der meteor.ste
DATENFORMAT 4 /* 0 - Stationsbezogene Daten (default, d.h. so wie bisher */
/* 1 - Massendatenformat */
/* 2 - Rasterdatenformat */
/* 3 - HYRAS-Datenformat */
/* 4 - HYRASmix - HYRAS zzgl. Stationsdaten */
/* 5 - REGNIEmix - REGNIE zzgl. Stationsdaten */
In der Stationstabelle enthält die Spalte mit der STATIONSKENNUNG (hier Name) die Nummern der Rasterzellen in den Zeilen, die die Daten im Massenformat (‚m‘ in Spalte TYP) enthalten und die Dateinamen der Klimadateien für die Klimastationen (‚kli‘ in Spalte TYP).
Bei der Ordnung der Einträge in der Stationstabelle ist darauf zu achten, dass zuerst die Daten im Massendatenformat stehen und zum Ende der Stationstabelle die Klimadateien folgen.
Auszug aus der met_stat.dbf

In der met_data.sdf wird analog zum HYRAS-Format angegeben, wie die Niederschlagsdatei heißt (hier \Raster\dummy.N). Die Klimareihen befinden sich im Verzeichnis \Raster\dummy unter den Namen, die in der met_stat.dbf angegeben sind (z.B. st_3934.kli).
###### Meteorologie ########################################################### MET_DATEN ASCII \Raster\Dummy TESTDRUCK Termin Termin TAG dd MONAT mm JAHR yy STUNDE hh *MINUTE min NIEDERSCHLAG N [mm/d] *LUFTTEMPERATUR T [°C ] *RELATIVE_FEUCHTE RH [%] *GLOBALSTRAHLUNG RG [j/cm²] *WINDGESCHWINDIGKEIT wind [m/s] POTENTIELLE_VERDUNSTUNG EP [1/10.tel mm/d] +++++++++++++++++++++++++++++++++++++++++++++++++++++++

ACHTUNG: Es muss darauf geachtet werden, dass die Spaltenbezeichnung für die meteorologischen Daten der Stationsdateien (N, RH, RG und T) und der Dateityp der jeweiligen HYRAS-Massendaten identisch sind.
Datenformat 5: REGNIEmix
Das Datenformat REGNIEmix funktioniert entsprechend dem HYRASmix Datenformat. Es wurde aber für eine sehr hohe Rasterauflösung (z.B. 1 km-Raster) zur Verringerung der Rechenzeit entwickelt. Die Flächenübertragung erfolgt hierbei nur für die Klimastationen und nicht für das Niederschlagsraster, da davon ausgegangen wird, dass das Raster hoch genug aufgelöst ist. Ein weiterer Unterschied zu dem HYRASmix Datenformat besteht in der Sortierung der Stationstabelle: hier müssen zuerst die Klimadateien und danach die Daten im Massendatenformat enthalten sein.
5.2.10 Regionale Verdunstungskorrektur
Über die Stationsdatei können regionale Verdunstungskorrekturfaktoren angegeben werden (hier Spalte „Kor_EP“). Die regionale Verdunstungskorrektur ist über das Steuerwort „VERDUNSTUNGSKORREKTUR“ in der met_stat.sdf anzugeben.
Stationsdatei.dbf
met_stat.sdf
###### Meteorologie ########################################################### Testdruck MET_STAT DBASE cli_stat_sa.dbf … VERDUNSTUNGSKORREKTUR KOR_EP +++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++ ############################################################################
5.2.11 Gewässerverdunstung
Die Verdunstung freier Wasserflächen (selektiert über den Landnutzungstyp „W“) wird in der Regel im Rahmen der Abflussbildung aus der potenziellen bzw. aktuelle Verdunstung berechnet. Über einen Korrekturfaktor im Modul met_mod1 kann die Wasserflächenverdunstung korrigiert werden. Der Eintrag in der modul.ste lautet:
EP_KORREKTUR_WASSER "Korrekturfaktor"
wobei der Default_wert für den Korrekturfaktor 1.2 ist.Für eine korrekte Abbildung der Gewässerverdunstung im Rahmen detaillierter Bilanzuntersuchungen kann es notwendig sein, diese in Abhängigkeit vom Wasserstand und der davon abhängigen Wasseroberfläche zu erfassen. Dazu stehen in ArcEGMO Möglichkeiten zur Einbindung von Ansätzen zur Verfügung, die die Verdunstung freier Wasserflächen in Abhängigkeit von der Wassertiefe (-temperatur) und weiteren meteorologischen Größen wie Lufttemperatur, Windgeschwindigkeit, relative Luftfeuchte und Globalstrahlung berechnen. Diese Ansätze können an die „besonderen Gewässerpunkte“ wie Talsperren und Seen gebunden werden. Über die für einige GWP-Typen verwalteten Höhen-Volumen-Oberflächen-Beziehungen kann dann in Abhängigkeit vom Wasserstand der jeweilige Verdunstungsverlust als Speicherinhaltsänderung ermittelt werden.
Mit dem Faktor EP_KORREKTUR_WASSER wird die sich für den Standort ergebende potenzielle Verdunstung der meteorologischen Modellierungseinheit (EFL, HYD, TG, KAS), in der sich der Gewässerpunkt befindet, multipliziert, um so die Gewässerverdunstung dieses Gewässerpunktes zu erhalten. Mit dem gleichen Korrekturfaktor wird auch die Wasserflächenverdunstung im Abflussbildungsmodell (Landnutzung W) ermittelt.
Wenn in der gwp.tab keine Koordinaten vorhanden oder für einzelne GWPs die Koordinaten mit 0 oder -9999 angegeben sind, kann keine Zuordnung der EP und PI-Werte der „übergeordneten“ met. Fläche erfolgen, EP und PI sind dann demzufolge 0.
Neben der programminternen Berechnung der Verdunstung kann aber auch eine Zeitreihe vorgegeben werden, die gemeinsam mit den Bewirtschaftungsgrößen eingelesen wird. Das vorzugebende Datenformat ist wep (für Gewässerverdunstung), als Raumbezug (RBT) muss GWP angegeben werden. Bei der Vorgabe einer Zeitreihe wird der Korrekturfaktor nicht ausgewertet, da davon ausgegangen wird, dass die vorgegebene Zeitreihe bereits korrigiert und modifiziert ist.
Weist diese Reihe Fehlstellen auf (=0. oder -9999., d.h. ein Verdunstungswert von 0. wird auch nicht als realistisch angesehen), wird auf die in berechnete Verdunstung der „übergeordneten“ met. Fläche zurückgegriffen.
Bw_file.tab
| DATEI | TYP | DATZ | FORM | RBT | RB | X-COORD | Y-COORD | DTD |
| Evaposee | txt | wep | E | gwp | 0 | 0 | 0 | 0 |
Um zu verhindern, dass der meteorologische Input in solche Wasserflächen im Rahmen der Abflussbildungsberechnung und bei der Modellierung der Gewässerpunkte und damit doppelt berücksichtigt wird, ist es notwendig, im Abflussbildungsmodell solche Gewässerflächen zu kennzeichnen, für die als Gewässerpunkt eine detailliertere Verdunstungsbetrachtung erfolgt.
Diese Gewässerflächen erhalten als Landnutzungstyp ein „P“ und werden damit im Abflussbildungsmodell nicht weiter betrachtet, d.h. sie erhalten für die Übergabe-/Ausgabegrößen einen Nullwert, was allerdings in Kartendarstellungen zu Problemen führt.
Es kann auch sinnvoll sein, extern ermittelte Gewässerverdunstungen bei der Modellierung der Wasserflächenverdunstung im Abflussbildungsteil von ArcEGMO zu nutzen.
Dazu muss den Elementarflächen, die innerhalb einer Wasserfläche bzw. einer infolge des Grundwasseranstiegs potenziellen Wasserfläche liegen, die ID des zugeordneten Gewässerpunktes zugewiesen werden. Dieser Gewässerpunkt muss natürlich auch innerhalb des Gewässernetzes als Geometrieelement vorhanden sein.
Diese Zuordnung erfolgt über das neue Attribut GewaesserpunktZuordnung im ElementarflächenCover, das in der efl.sdf dem Programm mitzuteilen ist.
Auszug aus der efl.sdf
EFL_PAT DBASE efl.dbf … GewaesserpunktZuordnung Gwp_ID /* Zuordnung zu einem Gewaesserpunkt */
Es ist sicherzustellen, dass Elementarflächen, die keinem Gewässerpunkt zugeordnet werden sollen, als Attribut für die Gewässerpunktzuordnung eine 0 oder einen Wert kleiner als Null aufweisen, so dass keine Verknüpfung mit dem GWP-Cover erfolgen kann. Fehlt der Eintrag GewaesserpunktZuordnung, so erfolgt auch keine Verknüpfung mit dem GWP-Cover und die Berechnungen der Wasserflächen verlaufen programmintern wie beschrieben.
Während der Abflussbildungssimulation wird für die EFL mit einer GWP-Zuordnung geprüft, ob für diesen GWP eine externe Verdunstungsreihe vorliegt. Wenn ja, werden die hier angegebenen Verdunstungswerte verwendet, sofern sie größer als Null sind. Sind sie kleiner oder gleich Null, werden diese als Lücke in der Zeitreihe interpretiert und dafür der interne Berechnungsansatz genutzt.
Da jetzt für die Gewässerpunkte nicht bekannt ist, ob die Gewässerverdunstung schon für die Elementarflächen berechnet wurde oder nicht, ist es notwendig, diesen einen Kennwert zuzuordnen, über den gesteuert werden kann, ob und wie die Meteorologie in der Volumenbilanzierung der Gewässerpunkte berücksichtigt werden soll.
In der gwp.sdf wurde dazu das Schlüsselwort Ansatz_metInput integriert, über das verschiedene Ansätze gewählt werden können, die die Wasserstandsänderung [m] als Differenz zwischen dem Niederschlag auf den Seekörper und die Verdunstung aus dem Seekörper für den aktuellen Zeitschritt liefern. Gewählt werden kann derzeit zwischen zwei Ansätzen:
- liefert immer 0 und ist dann auszuwählen, wenn der meteorologische Eingang auf die Wasserflächen, die auch über die GWP erfasst werden, im Abflussbildungsteil berücksichtigt wird,
- hier wird für die Gewässerverdunstung eine externe Zeitreihe verwendet, sofern diese vorliegt, ansonsten die Verdunstung aus der potenziellen Verdunstung (Erhöhung um einen festen Faktor) abgeleitet,
- …3,4,5, … sind für weitere Ansätze vorgesehen, die z.B. in Abhängigkeit von der Wassertiefe, der Windexposition und/oder der Wassertemperatur die Gewässerverdunstung berechnen.
Der zu verwendende Ansatz kann global, d.h. einheitlich für alle Seen und Talsperren im Modellgebiet vorgegeben werden, indem der anzuwendende Ansatz (derzeit 0 oder 1) direkt über das Schlüsselwort Ansatz_metInput vorgegeben wird. Beginnt der Eintrag hinter dem Schlüsselwort mit dem Buchstaben a, wird der Eintrag als Name eines Attributes in der Attributtabelle des GewässerpunktCovers interpretiert. Darüber sind dann also auch differenzierte Vorgaben für jeden Gewässerpunkt möglich. Wird das Attribut in der Gewässertabelle nicht gefunden oder besitzt es nicht interpretierbare Einträge (derzeit nur 0 oder 1) oder das Schlüsselwort Ansatz_metInput selbst wird in der Einträge wird in der gwp.sdf nicht gefunden, wird für die betreffenden Gewässerpunkte mit dem Ansatz 0 gearbeitet.
Auszug aus der gwp.sdf
GWP_PAT DBASE gwp.dbf
…
Ansatz_metInput a1 /* Hier kann angegeben werden, wie der */
/* met. Input in den Gewaesserpunkt be-*/
/* ruecksichtigt werden soll */
/* Ist das Schluesselwort nicht angege-*/
/* ben, wird bei der ungekoppelten Modellierung*/
Neben den freien Wasserflächenflächen, für angenommen wird, dass sie innerhalb eines Simulationszeitraumes existieren, ergeben sich im Rahmen der gekoppelten Modellierung mit Grundwasserströmungsmodellen auch Flächen, die nur temporär unter Wasser stehen und deshalb keine Landnutzungskennung W aufweisen. Auch diese Flächen werden dann, wenn sie überstaut sind, hinsichtlich ihrer Verdunstung wie Wasserflächen behandelt. Detailliertere Informationen dazu erfolgen im Rahmen der Dokumentationen zu den Modellkopplungen.
[1] Wert der Messung um 14 Uhr
[3] HYRAS: Erstellung hydrologisch relevanter Raster- und Gitterpunktdatensätze für internationale Flussgebiete mit deutschem Gebietsanteil (ohne Oder und Maas, Donau teilweise) auf der Basis qualitätsbewerteter meteorologischer Beobachtungsdaten. Zugang über AG. Jede Rasterzelle bedeckt eine Fläche von ca. 25 km².
5.3 Hydrologische Daten
5.3.1 Pegeldaten
Die Verwaltung hydrologischer Eingangszeitreihen und ihre Zuordnung auf die zu modellierenden Raumelemente erfolgt in der Programmkomponente HYD_DATA.
Sie bietet derzeit folgende Funktionalitäten:
- Verwaltung gemessener Wasserstände und Abflüsse und
- räumliche Verknüpfung dieser Zeitreihen mit Gewässerabschnitten.
Die Verwaltung der Daten erfolgt analog zu den meteorologischen Eingangsgrößen in Tabellen. Im Gegensatz zu den meteorologischen Daten, die notwendig für die Modellierung sind, ist die Einbeziehung obiger, hydrologischer Größen nur dann erforderlich, wenn während der Modellrechnung, z.B. für eine Eichung, ein Vergleich mit gemessenen Abflusswerten erfolgen soll.
Über die Steuerdatei HYD_DATA.STE (s. Abbildung 5.3-1) werden dem Programm die Namen der Dateien mitgeteilt, die die Strukturdefinitionen der Datendateien beinhalten. Unterschieden wird zwischen
- einer Stammdatentabelle (Strukturdefinition über HYD_STAT_DESCRIBE) und
- einer Datentabelle (STRUKTURDEFINITION über HYD_DAT_DESCRIBE).
Über den Eintrag FEHLWERTBELEGUNG kann angegeben werden, wie Fehlwerte in den Zeitreihen definiert worden sind. Default-Wert ist der Wert –9999.
###### Hydrologie ###########################################################
HYD_STAT_DESCRIBE hyd_stat
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
HYD_DAT_DESCRIBE hyd_data
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
FEHLWERTBELEGUNG FEHLWERT /* Kennzeichnung nichtgemessener Daten */
/* z.B. Geraeteausfall */
+++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
Abbildung 5.3-1: Steuerdatei HYD_DATA.STE
Abbildung 5.3-2 zeigt die Datei HYD_STAT.SDF zur Definition der Stammdatentabelle, die über das Schlüsselwort HYD_STAT eingeleitet wird. Hier wird die Struktur der DBASE-Tabelle PEGEL.DBF beschrieben, die als Attribute eine verbale Bezeichnung für die Lage des Pegels, eine Datendateibezeichnung, den Datentyp, die zeitliche Auflösung und die Lagekoordinaten definiert.
Die Zuordnung der hydrologischen Daten kann über die Angabe
- der Gewässerstrecke <FGW-ID>,
- des Teileinzugsgebietes <TG-ID> oder
- der Lagekoordinaten der Station erfolgen.
Sind mehrere dieser Attribute angegeben, werden bevorzugt die IDs verwendet, wobei die Wahl zwischen den IDs wiederum durch die gewählte Raumauflösung bei der Abflusskonzentrationsmodellierung bestimmt wird.
Ist keine ID vorgegeben, wird unter Nutzung der Lagekoordinaten der jeweils nächste Gewässerabschnitt (aus den Knotenkoordinaten) bzw. das nächste Teileinzugsgebiet (nach den Koordinaten des Flächenschwerpunktes) für die Zuordnung verwendet.
Diese Zuordnung ist in beiden Fällen mit Unsicherheiten behaftet. So muss die Selektion des zugeordneten Gewässerabschnittes über den oberen Knoten erfolgen, weil nur so überhaupt eine Eindeutigkeit gesichert ist (bei den in ArcEGMO zugelassenen Baumstrukturen des Gewässernetzes können mehrere Gewässer denselben unteren Knoten besitzen).
Pegelabflüsse werden programmintern u.a. zur Schätzung bestimmter Anfangszustände (insbesondere der Grundwasserspeicher) verwendet. Für diese Schätzung ist die Kenntnis der Einzugsgebietsflächen der Pegel erforderlich. Diese Einzugsgebietsflächen werden normalerweise innerhalb des Programms gleich den kumulativen Einzugsgebietsflächen der zugeordneten Gewässerabschnitte bzw. Teileinzugsgebiete gesetzt. Wenn allerdings die Lage der Pegel nicht bei der Gebietsgliederung berücksichtigt wurde, ergeben sich bei dieser Verfahrensweise größere Differenzen zu den wirklichen Pegeleinzugsgebieten. In solchen Fälle können die EINZUGSGEBIETSFLAECHEn der Pegel auch direkt vorgegeben werden (Einheit [m2]).
Über den DATENFAKTOR können Korrekturen/Umrechnungen der Zeitreihen vorgenommen werden. Alle Pegelabflüsse werden mit dem Datenfaktor multipliziert. Ist er nicht angegeben, wird er auf 1. gesetzt. Über die Angabe von -1 kann eine Entnahme der Abflusszeitreihe vorgenommen werden, wenn die ID’s der zugeordneten Gewässerabschnitte ein negatives Vorzeichen erhalten (siehe Kapitel 5.4.1).
HYD_STAT DBASE pegel.dbf /* Tabelle der Pegel */ VERBALE_ORTSBEZEICHNUNG NAME /* Pegelname oder Lagebezeichnung */ GEWASSERSTRECKE FGW_ID TEILEINZUGSGEBIET TG_ID DATEI_BEZEICHNUNG DATEI DATEN_TYP TYP DATENZEITINTERVALL DTD X_WERT X_COORD Y_WERT Y_COORD EINZUGSGEBIETSFLAECHE AREA [qm] DATENFAKTOR FAKTOR /* Datenfaktor für Korrektur/Umrechnung */
Abbildung 5.3-2: Datei HYD_STAT.SDF – Definition der Stammdatentabelle
Abbildung 5.3-3 beinhaltet die Stammdatentabelle. Diese befindet sich, sofern es sich um eine ASCII-Tabelle handelt, im Verzeichnis GISDESCRIBE. Hier ist zu sehen, dass die Reihenfolge der Spalten nicht mit der Definitionsreihenfolge in der Steuerdatei übereinstimmen muss.
FGW-ID DATEI TYP DTD NAME X-COORD Y-COORD 40 test wqt 24 'Pegelname' 4472131.000 5709110.000
Abbildung 5.3-3: Beispiel für eine Stammdatentabelle
Die Datei HYD_DATA.SDF beinhaltet die Strukturdefinition für die eigentlichen Datentabellen (s. Abbildung 5.3-4) und wird über das Schlüsselwort HYD_DATEN eingeleitet. Die Datentabellen sind i.d.R. ASCII-Tabellen. Der Dateiname setzt sich aus der DATEI_BEZEICHNUNG und dem DATEN_TYP zusammen. Als Datentyp ist ‘wt’, ‘qt’ oder ‘wqt’ möglich, je nachdem, ob Wasserstände, Abflüsse oder beides in der zugeordneten Datentabelle verwaltet werden. Bezüglich der zeitlichen Auflösung gilt, wiederum analog zu den meteorologischen Daten, dass diese für alle Daten gleich sein muss.
Neben den Datenarten werden wiederum die Attributbezeichnungen für die zeitliche Zuordnung festgelegt. Standardmäßig werden die Datentabellen im Zeitreihen-Verzeichnis gespeichert, und zwar alle Daten einer Station in einer Datendatei.
Es ist aber auch möglich, die Zeitreihendaten in einem projektunabhängigen Verzeichnis zu verwalten, beispielsweise um Redundanzen zu vermeiden. In diesem Fall wird neben dem Datenformat (ASCII- oder DBASE) auch der Pfad zu diesen Datendateien angegeben. Zu beachten ist hierbei, dass der komplette Pfad angegeben wird und dass die Pfadangabe mit einem Slash abgeschlossen wird.
HYD_DATEN ASCII H:\Alle_Zeitreihen Termin termin /* durch "." getrennte Datumszeichenkette */ JAHR y MONAT m TAG d STUNDE h MINUTE min GEMESSENER_PEGELABFLUSS QT [m**3/s] GEMESSENER_WASSERSTAND WT [cm]
Abbildung 5.3-4: Datei HYD_DATA.SDF – Definition der Datentabellen
Abbildung 5.3-5 zeigt einen Auszug aus der Pegeldatentabelle TEST.WQT, die entsprechend des Datentyps ‘wqt’ Abflusswerte und Wasserstände beinhaltet.
d m y QT WT 01 11 1978 0.20 0.5 02 11 1978 0.25 0.51 03 11 1978 0.30 0.52 04 11 1978 0.25 0.51
Abbildung 5.3-5: Beispiel für eine Pegeldatentabelle
5.3.2 Externe Zuflüsse zum Gewässer
Am Gebietsrand sind Fremdzuflüsse zu verwenden. Sie berücksichtigen die außerhalb des Modellgebiets gelegene Flächengröße des Einzugsgebiets. Dazu muss die Externe Einzugsgebebietsgröße an den jeweiligen Rand-FGW-Abschnitten, die von dem Fremdzufluss gespeist werden, über das Steuerwort „FGW_extZuflussgebiet“ in der fgw.sdf und einer neuen Spalte mit der Flächengröße am fgw.dbf angegeben werden.
Zuordnung der Einzugsgebietsflächen zum Gewässernetz
Sofern für die Modellebene Q_Mod auf der Basis von Gewässerabschnitten gearbeitet wird, wird vom Programm eine Datei fgw_area.xlx im <Ergebnisverzeichnis>para ausgegeben. Diese beinhaltet für jeden Gewässerabschnitt die folgenden Größen:
Tabelle 5-5.3-1: Auszug aus der Datei fgw_area.xlx
| e_area | Eigeneinzugsgebiet, das sich durch längengewichtete Aufteilung der zugeordneten Teileinzugsgebietsfläche auf sämtliche Gewässerabschnitte in diesem Einzugsgebiet ergibt |
| k_area | kumulatives Einzugsgebiet, das sich aus der Summe des aktuellen Eigeneinzugsgebietes und der Einzugsgebiete aller oberliegenden Gewässerabschnitte ergibt, |
| g_area | Grundwassereinzugsgebiet, das sich durch Auswertung der Kennungen für den Grundwasseranschluss ergibt (nur für detaillierte Grundwassermodellierung interessant) |
Diese Werte sind vor allem für die Darstellung des Gewässernetzes nützlich, weil so sehr schnell die Hauptgewässer identifiziert werden können.
Sämtliche Flächengrößen wurden bisher aus den Flächen der Einzugsgebiete im Modellierungs-Cover TG abgeleitet.
Wenn wesentliche Randzuflüsse ins Modellgebiet integriert wurden, war es bisher nicht möglich, ohne großen Aufwand die zugeordneten Einzugsgebiete dieser Zuflüsse in obige Flächenberechnung einzubeziehen.
Dies ist jetzt möglich, indem der Gewässerdatenbasis ein zusätzliches Attribut zugewiesen wird, das die dem externen Zufluss zugeordnete Einzugsgebietsfläche [km2] beinhaltet. Der Name dieses Attributs wird dem Programm über den neuen Eintrag FGW_extZuflussgebiet in der Datei …GISDescribefgw.sdf wie folgt mitgeteilt:
FGW_extZuflussgebiet f_area
Abbildung 5.3-6: Auszug aus der Datei …GIS\Describe\fgw.sdf
Fremdzuflüsse werden allein über die Pegel-Tabelle organisiert. In der Pegel.dbf wird die ID des Fließgewässerabschnitts mit einem Minuszeichen versehen. Ein Eintrag in der GWP.tab ist nicht erforderlich.
Name DATEI FGW_ID TG_ID TYP DTD AREA FAKT meisd meisdorf -6 6 qt 24 184000000 1
Abbildung 5.3-7: Auszug aus der Datei …GIS\ascii.pat\pegel.dbf
Die Abflussreihen der Fremdzuflüsse werden unter …Zeit.dat\Hyd.data<Pegelname>.tab gespeichert.
Über die Angabe eines negativen Datenfaktors (siehe Kapitel 5.4.1) in der Pegeltabelle kann eine Entnahme vorgenommen werden.
5.3.3 Pegel – Simulationsergebniszuordnung
Für die Ausgabe der Gütekriterien für jeden Pegel ist es jetzt auch möglich, nicht nur wie bisher den Abfluss des Gewässerabschnittes „qc“ mit der Pegelzeitreihe zu vergleichen, sondern auch mit dem Abfluss des Oberliegers „qo“ zu vergleichen.
Dazu muss in der hyd_stat.sdf das Steuerwort SIM_ERGEBNISZUORDNUNG angegeben werden. Es wird intern nur auf qo getestet. Wenn ungleich oder diese Spalte nicht gegeben ist, bleibt alles wie bisher.
hyd_stat.sdf
SIM_ERGEBNISZUORDNUNG Qc_oder_qo /* getestet wird intern nur auf qo, wenn */
/* ungleich oder diese Spalte nicht */
/* gegeben ist, alles wie bisher */
5.3.4 PI2Pegel
Über die Aktivierung des Steuerwortes „PI2Pegel“ in der hyd_data.ste wird die Tabelle „pegel2tg.txt“ erzeugt.
hyd_data.ste
###### Hydrologie ##########################################################
HYD_STAT_DESCRIBE hyd_stat
++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
HYD_DAT_DESCRIBE hyd_data
++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
*PI2Pegel 1
FEHLWERTBELEGUNG -999. /* Kennzeichnung nichtgemessener Daten */
/* z.B. Geraeteausfall */
++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++
################################################################################
Diese Tabelle enthält die Zuordnung des Pegeleinzugsgebietes (alle zugehörigen TGs) zur PegelID (z.B. zur Messstellennummer) und deren Flächenanteil am Pegeleinzugsgebiet.
pegel2tg.txt
Pegel TG_ID Anteil
563745 376 0.632732
563745 379 0.343717
563745 377 0.006020
563745 375 0.017531
568400 319 0.175335
568400 274 0.198216
568400 306 0.113704
568400 273 0.161592
568400 265 0.175977
568400 259 0.175176
Es wird für alle Pegel, an denen Zeitreihen vorliegen, das Pegeleinzugsgebiet ermittelt. Danach stoppt ArcEGMO automatisch. Für eine Simulation muss nach erfolgter Ausgabe der Zuordnungstabelle das Steuerwort PI2Pegel wieder deaktiviert werden.
Wenn in der hyd_stat.sdf keine Pegelkennung angegeben ist, erhalten alle Pegel eine fortlaufende ID. In der hyd_stat.sdf kann über das Steuerwort „Pegelkennung“ eine PegelID/-Kennung (z.B. die Angabe der Messstellennummer) aktiviert werden (Pegelkennung PEG_MSTNR).
hyd_stat.sdf
###### Hydrologie ######################################################## … Pegelkennung PEG_MSTNR … ++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++ ################################################################################
Über die Ausgabe der Ergebnisse auf Teileinzugsgebiete können die Simulationsergebnisse mit dem Programm table.exe flächengewichtet für Pegeleinzugsgebiete aggregiert werden. Dafür ist die einmalige Erzeugung der Tabelle pegel2tg.txt notwendig. Der Befehl für table.exe lautet „PegelPi“ und die zugehörige Beschreibung ist der Dokumenation Tools zu entnehmen.
5.4 Zeitfunktionen in ArcEGMO zur Bewirtschaftung
Zeitfunktionen bieten in ArcEGMO die Möglichkeit, zeitlich veränderliche Randbedingungen vorzugeben. Über Zeitfunktionen können folgende Bewirtschaftungen abgebildet werden:
- Gewässernutzung, bei der sowohl in das Oberflächengewässer als auch in das Grundwasser Einleitungen (+) oder Entnahmen (-) in das Modell eingespeist oder entnommen werden.
- Stoffeinträge oder Stoffentnahmen für Chlorid, Phosphor und Stickstoff
- Vorgabe von Abflusskomponenten: Oberliegerzufluss (qo), Durchfluss (qc), Direktzufluss (qd) und Basisabfluss (qb). Zur Abbildung von Fremdzuflüsse, Einspeisungen, Entnahmen, Überleitungen, Abflussnachführungen etc.
- Vorgabe von Wasserständen z.B. als Randbedingung für Grundwassermodell
- Entnahme aus Gewässerpunkten, z.B. als Gewässerverdunstung
- Wechselnde Mindestwasserabgaben an Unterliegern und/oder veränderbarer Zielwasserstand in Talsperren
- Zeitliche Steuerung von Bauwerken über den K1 Parameter (=> sie Beschreibung Gewässerpunkte) vor allem zur Vorgabe von Wehrhöhen
Diese sind in der Realität meist durch anthropogene Eingriffe verursacht und werden daher unter dem Überbegriff „Bewirtschaftung“ über die Datei BW_DATA.STE direkt im ArcEGMO Verzeichnis organisiert. Die Steuerungsdatei Datei BW_DATA.ste verweist auf die eigentlichen Datendateien (z.B. bw_file.sdf und bw_file.tab für die Verwaltungsdatei) wie Abbildung 5.4-1 darstellt.
In der Strukturdefinitionsdatei sind anhand der möglichen Einträge und der Kommentare verschiedene Möglichkeiten für die Bindung der Einleitungen und Entnahmen auf Datenarten und Raumbezüge definiert. Dies sind allerdings vor allem Einstellungen, die für den Bewirtschaftungsmodus von ArcEGMO von Interesse sind.
Tabelle 5.4-1: Kodierung der durch die Zeitfunktionen ansteuerbaren Größen
| Kodierung | Erläuterung | Einheit |
| q_ex, gw | Gewässernutzungen im Oberflächengewässer und im Grundwasser, die als Einleitungen (+) oder Entnahmen (-) ins Modell eingespeist werden | m3/s |
| qex_Cl,qex_P,qex_N | analog für Chlorid, Phosphor und Stickstoff | g/s |
| qo, qc, qd, qg | gemessene und/oder extern berechnete Zuflüsse ins Modellgebiet, mit denen die angegebene Systemgröße (qo – Oberliegerzufluss, qc – Abfluss, qd – Direktzufluss, qg – Basisabfluss) überschrieben werden können, d.h. einsetzbar beispielsweise:- Einspeisung von Pegelreihen als Fremdzuflüsse ins Gebiet am „Modellrand“à qo,- Messreihe einer Talsperrenabgabe ersetzt modellierten Abfluss im Sinne einer Nachführung à qc- Einspeisung simulierter Grundwasserzuflüsse eines externen Grundwassermodells à qg | m3/s |
| Wc | Wasserstände im Gewässer als Randbedingung für internes Grundwassermodell | m üNN |
| Wep | Gewässerverdunstung (GWP zugeordnet) (positive Werte) | mm |
| ql, qnu,qndqzb | Mindestabgabe, Nutzungsbedarf der Unterlieger und Nutzungsbedarf direkt aus der TalsperreZwischengebietszufluss zu einem Kontrollpegel, | m3/s |
| Sw | aktuell anzusteuernder Wasserstand in der TS | m üNN |
| k1 | Aktueller Wert des Parameters K1 (s. Teil 1, Kap. 4, Tab. 4.18), vor allem zur zeitveränderlichen Vorgabe von Stauhöhen an Wehren gedacht – aktuelle Wehrhöhe | m üNN |
| Intz | Intz_Input als Beregnung- Zuordnung auf die InterzeptionsSpeicherfuellung | mm/DT |
| bru | Grundwasserentnahmen oder Einleitungen in ASM | m3/s |
| rnd | Randzufluesse in ASM | m3/s |
| qero_N, qero_P | akt. partikulärer Stoffeinleitung (N oder P) ins Gewässer über RO (Erosion) | g/s |

Abbildung 5.4-1: Vereinbarung von zeitvariablen Einleitungen/Entnahmen
Für die Einbindung von Zeitreihen werden die in der Verwaltungsdatei …\gis\ascii.dat\bw_file.tab weitere Angaben benötigt. Die Datei-Form M, E oder R legt fest, ob die mehrere Datenarten für einen Raumbezug gegeben sind (M) oder eine Datenart für mehrere Raumbezüge (E und R). R und E unterschieden sich dabei nur über die Lage der betroffenen IDs: R wird für alle RandIDs verwendet, E steht für alle IDs innerhalb des Randes.
Der Raumbezug wird angegeben, damit die Zuordnung der IDs zu den entsprechenden Elementen vorgenommen werden kann. Dabei ist sicherzustellen, dass der angegebene Raumbezugstyp RBT mit dem gewählten Raumbezug der Modellierung (s. RAUMBEZUEGE_MODELLIERUNG in Kapitel 3) für die jeweilige Modellebene (Q für oberflächengewässer- und GW für grundwasserrelevante Nutzungen) übereinstimmt. Während die Seeverdunstung für einen Gewässerpunkt vorgegeben werden kann, sind Einleitungen und Entnahmen (qex) NUR für Fließgewässerabschnitte möglich. Eine Einleitung in einen See muss über den Fließgewässerabschnitt erfolgen, der dem Gewässerpunkt des Sees zugeordnet ist.
Die zeitliche Variabilität der Gewässernutzungen kann angegeben werden, wie in Kapitel 8.5 beschrieben, über zyklische Zeitfunktionen, die einen typischen Jahresgang beschreiben. Dies kann über mittlere Monatswerte oder über Stützstellen, anzugeben über die Tagesnummer innerhalb eines Jahres (1…365) erfolgen.
Soll für Testzwecke eine Zeitfunktion mal deaktiviert werden, ohne dass die entsprechende Zeile komplett gelöscht wird, kann das leicht geschehen, indem die DATEI mit einem ‚*’ auskommentiert wird.
DATEI TYP DATZ FORM RBT RB X-COORD Y-COORD DTD *einleitung txt qex E fgw 0 0.0000 0.0000 0 *einleitung txt qex E fgw 0 0.0000 0.0000 0 Evaposee txt wep E gwp 0 0.0000 0.0000 0 Wehr11 txt k1 E gwp 0 0.0000 0.0000 0 *Wehr13 txt k1 E gwp 0 0.0000 0.0000 0 *Wehr14 txt k1 E gwp 0 0.0000 0.0000 0
Abbildung 5.4-2:Beispiel einer Verwaltungsdatei…gis\ascii.dat\bw_file.tab
Zeitfunktion Zustand
Über die Zeitfunktion Zustand können Bauwerke aktiviert und deaktiviert werden. Standardmäßig sind alle Bauwerke aktiv, die in der GWP-Datei vorgegeben sind.
Die Zustände zus als neue, programminterne Datenart werden über Bewirtschaftungsdaten aktiviert. Während der Dateiname und der Dateityp frei vorgegeben werden können, muss zus für DATZ als Datenart angegeben werden, der die einzulesenden Zustände programmintern zugeordnet werden. Als Raumbezug wird derzeit nur GWP unterstützt.
Bw_file.dat
DATEI TYP DATZ FORM RBT RB X-COORD Y-COORD DTD TS_Zustand txt zus E gwp 0 0 0 864000
Die Datendatei TS_Zustand.txt befindet sich im Zeitreihenverzeichnis im Ordner bw_data. Je nach gewählter Zeitfunktion (s. Kapitel 5.6) können die Zustände zyklisch, z. B. als Jahresgänge (Wehr gezogen oder gesetzt), als äqui- oder nicht äquidistante Zeitreihe vorgegeben werden. Im folgenden Beispiel besteht die Zustandsdatei aus wenigen Stützstellen, die besagen, dass am 1.11.1965 das Bauwerk (hier Talsperre) in Betrieb ging, am 2.11.1993 deaktiviert wurde (z. B. für Baumaßnahmen) und am 3.11.1994 wieder in Betrieb genommen wurde.
Die hier gewählte Vorgabe der Zustände über Stützstellen funktioniert dann gut, wenn der Simulationsbeginn innerhalb des über die Stützstellen definierten Zeitraumes liegt. Beginnen die Simulationsrechnungen vor dem ersten Eintrag in der Zustandsdatei, so ist der Zustand nicht definiert. In diesem Fall wird eine Warnung ausgegeben und der Zustand auf 0 gesetzt. In dem Beispiel unten wäre dies korrekt, da die Talsperre erst im Jahr 1965 in Betrieb genommen wurde.
TS_Zustand.txt
termin 113 01.11.1965 1 02.11.1993 0 03.11.1994 1
Alternativ kann natürlich der Zustand auch für jeden Tag vorgegeben werden.
Derzeit werden als Zustände nur 0 für deaktiviert oder nicht wirksam und 1 für aktiviert unterstützt.
Um den Zustandswechsel zwischen 0 und 1 zu berücksichtigen z. B. für die Inbetriebnahme einer bisher nicht vorhandenen Talsperre, ist dafür zu sorgen, dass der Speicher zu Beginn einer Simulationsperiode leer und der Startwasserstand dementsprechend festgelegt ist, sofern diese mit deaktivierter Talsperre beginnt. Dieser Startwasserstand bezieht sich auf die Bezugshöhe und muss dem minimalen Wasserstand in der HAV- und WQB-Tabelle entsprechen.
Ein Zustandswechsel von 1 zu 0 bewirkt derzeit eine Deaktivierung des Bauwerkes. Die Speicherfüllung und der letzte Wasserstand verbleiben unverändert bis zu einer eventuellen Wiederinbetriebnahme (Wechsel von 0 zu 1), was sicherlich für längere Zeiträume nicht realistisch ist.
Deshalb ist vorgesehen, sofern dies für die Lösung konkreter Aufgabenstellungen erforderlich wird, weitere Zustände bzw. Zustandsübergange wie gesteuerte Entleerung für Wartungsarbeiten (z. B. Entleerung mit dem schadlos abführbaren Abfluss) oder Dammbruch mit einer schlagartigen Entleerung zu integrieren.
5.4.1 Einleitungen und Entnahmen
5.4.1.1 Integration analog Pegelreihen
Einleitungen und Entnahmen sind anthropogene, Bilanz beeinflussende Maßnahmen in einem Flussgebiet. Derartige Einflüsse sollten, sofern sie quantifizierbar sind, im Rahmen einer hydrologischen Gebietsmodellierung berücksichtigt werden.
In ArcEGMO können Einleitungen bzw. Entnahmen als Zeitreihen vorgegeben und über ihren Raumbezug an die Modellierungs-Cover gebunden werden.
Die Verwaltung dieser Zeitreihen erfolgt vollkommen analog und letztlich auch gemeinsam mit den hydrologischen Daten.
In der hydrologischen Stammdatentabelle (s. Abbildung 5.3-3) werden die Verweise auf die Zeitreihen mit Entnahmen und Einleitungen genauso verwaltet wie die Pegelzeitreihen. Lediglich die ID’s der zugeordneten Gewässerabschnitte bzw. Teileinzugsgebiete erhalten zur Unterscheidung von den Pegelreihen ein negatives Vorzeichen.
Bei Verwendung dieser einfachen Methode ist es erforderlich, dass die Einleitungen oder Entnahmen in gleicher zeitlicher Auflösung wie die Pegeldaten und die meteorologischen Daten vorliegen.
5.4.1.2 Integration als Zeitfunktionen
Eine andere, wesentlich flexiblere Möglichkeit, Einleitungen und Entnahmen in ArcEGMO zu berücksichtigen, besteht in der Verwendung von Zeitfunktionen.
5.4.1.3 Integration von GRM-Daten
Eine weitere Möglichkeit, Einleitungen und Entnahmen in ArcEGMO einzubinden, wurde über eine Schnittstelle zu den Datenstrukturen geschaffen, die in ArcGRM© zur Verwaltung von Nutzerdaten gebräuchlich sind.
Insbesondere für die Einspeisung externer Zuflüsse inklusive Stoffkomponenten wurden die Möglichkeiten der Zeitreihenverwaltung erweitert um die DATEI_FORM K (s. Dokumentation Teil 1, Kapitel Bauwerke), mit der es nun möglich ist, einem Raumbezug (einem räumlichen Objekt) mehrere Datenreihen über eine Datei zuzuordnen.
Die Zuordnung des Raumbezugs erfolgt nun in der Datei bw_file.tab. Im nachstehenden Beispiel werden ein externer Zufluss inklusive Chloridfracht in den Gewässerabschnitt mit der FgwID = 2000 eingespeist. Die Zuordnung zur Datenart DATZ erfolgt nicht mehr in der Datei bw_file.tab, sondern in der Datentabelle selbst. Hier muss als Attributbezeichnung DATZ gemäß obiger Tabelle angegeben werden. Das Attribut DATZ in bw_file.tab wird überlesen.
DATEI TYP DATZ FORM RBT RB X-COORD Y-COORD DTD cl_test txt xxx K fgw 2000 0 0 1440
Abbildung 5.4-3: Datei…gisascii.patbw_file.tab
cl_test.txt D M Y qex_Cl qex 1 1 1992 0.9167 0.123456 2 1 1992 1.2696 0.98765
Abbildung 5.4-4: Beispiel Entnahme
5.4.1.4 Integration der Gewässerverdunstung als vorgegeben Zeitreihe (Messwerte)
Für die zeitgesteuerte Vorgabe der Gewässerverdunstung (WEP) ist zu beachten, dass die vorgegebenen Werte > 0 sein müssen, da Werte <= 0 als Fehlwerte interpretiert werden. Für diesen Fall wird die Gewässerverdunstung aus den Klimagrößen der nächstgelegenen Klimastation nach Turc/Ivanov berechnet. Die nächste Klimastation wird dabei aus den Koordinaten des Gewässerpunktes ermittelt. Sind keine Koordinaten angegeben, ist eine Ermittlung nach Turc/Ivanov nicht möglich. Sind in einer vorgegebenen Zeitreihe Verdunstungen mit „0“ angegeben, die verwendet werden sollen, ist es möglich, diese über das Löschen der Koordinaten (Koordinate = 0) des Gewässerpunktes mit zu berücksichtigen.
5.5 Externe Grundwasserzuflüsse
Sollen Grundwasserzuflüsse, die extern z.B. mit einem detaillierten Grundwassermodell berechnet wurden, innerhalb eines komplexen Flussgebietsmodells genutzt werden, übernimmt die Programmkomponente FE für diese Grundwasserzuflüsse
- die räumliche Zuordnung zu Gewässerabschnitten und
- die richtige zeitliche Bereitstellung innerhalb der Modellierung.
Extern berechnete Grundwasserzuflüsse sind in einer Datei bereitzustellen, deren Struktur dem ASCII-Export-Format der Tabellenkalkulation EXCELentspricht. Diese Dateistruktur wurde gewählt, weil extern berechnete Daten i.d.R. einer vorherigen Plausibilitätsprüfung unterzogen werden sollten, wozu Excel gut geeignet ist.
Abbildung 5.5-1 zeigt die zugehörige Definitionstabelle GW_DATA.SDF, die sich im Verzeichnis ZEIT.DATDESCRIBE befindet. Über diese Datei wird außerdem festgelegt, auf welche Datentabelle zugegriffen werden soll.
############################################################################# BERECHNETER_GW_ZUFLUSS ASCII gw_zu2 biln34a [m**3/s] ZEIT time #############################################################################
Abbildung 5.5-1: Datei GW_DATA.SDF – Definition der Datentabellen
Abbildung 5.5-2 zeigt beispielhaft einen Auszug aus einer solchen Datentabelle. Diese hat keine Ähnlichkeit mit den Datentabellen der hydrologischen Messwerte oder der meteorologischen Eingangsgrößen. In der ersten Spalte ist zwar wiederum die zeitliche Zuordnung zu erkennen, allerdings hier durch ‘.’ getrennt, während als Spaltentrenner das Semikolon genutzt wird.
Im Gegensatz zu den bisher beschriebenen Datentabellen wird hier die räumliche Zuordnung direkt über die Spaltenbezeichner realisiert. Spaltenbezeichner sind hier also bis auf ‘time’ die ID’s der Gewässerabschnitte, denen die Grundwasserzuflüsse zugeordnet werden sollen.
Programmintern wird dazu das BASEFLOW-Attribut des FGW-Covers (s. Kapitel 4) herangezogen. Wie in Kapitel 4.3 beschrieben wurde, können mehrere Gewässerabschnitte die gleiche Zuordnung besitzen. In diesem Fall werden für die Aufteilung der Grundwasserzuflüsse Aufteilungsfaktoren entsprechend der Flächenverhältnisse der Eigeneinzugsgebiete der Gewässerabschnitte zueinander ermittelt.
Wie an den Zeitbezügen erkennbar ist, liegen in der Beispielstabelle die Grundwasserzuflüsse in einer zeitlichen Auflösung von 15 Tagen vor. Sofern die Berechnungszeitschrittweite geringer ist, wird programmintern die richtige zeitliche Zuordnung gewährleistet, indem z.B. bei Tageswertrechnungen für 15 Tage derselbe Grundwasserzufluss verwendet wird.
time; 1; 2; 3; 4; 5; 6; 7 01.01.1979; 0.013176; 0.019608; 0.016587; 0.017185; 0.013512; 0.009487; 0.018423 16.01.1979; 0.004993; 0.012557; 0.0107; 0.009918; 0.007566; 0.004729; 0.014518 31.01.1979; 0.00103; 0.008819; 0.0077; 0.006568; 0.005981; 0.002848; 0.013556
Abbildung 5.5-2: Beispiel für eine Grundwassertabelle
5.6 Zeitvariante Daten -> relate Zeitfunktionen
Die Kennwerte in Relate-Tabellen werden vom Rahmenprogramm als zeitlich nicht veränderliche Größen verwaltet. Dies ist für eine Reihe von Kennwerten (Gefälle, Exposition, Bodenform) innerhalb der betrachteten Zeithorizonte gerechtfertigt und auch für andere Größen z.B. der Landnutzung für eine Vielzahl von Aufgabenstellungen möglich.
Für spezielle Untersuchungen ist es jedoch notwendig, Kennwerte als zeitlich veränderliche Größen zu behandeln.
Dies ist u.a. dann der Fall, wenn
- die Vegetationsentwicklung berücksichtigt werden soll (innerjährlicher Gang und langfristiges Wachstum) oder
- die Auswirkungen von Landnutzungsänderungen abzuschätzen sind.
- der innerjährliche Gang der Grundwasserflurabstände berücksichtig werden soll.
Modellmäßig beschreibbar sind diese Entwicklungen, indem
- für definierte Relationstypen Zeitfunktionen bestimmter Kennwerte vorgegeben werden (z.B. Relationstyp Nutzung: Versiegelungsgrad, Wurzeltiefe, Bedeckungsgrad) oder
- für definierte Relationstypen eine zeitliche Abfolge der Relationsklassen vorgegeben werden (z.B. Relationstyp Nutzung: Nutzungsklasse Wald wird zu buschiger Vegetation und später zu Grasland/Steppe).
Allerdings gelten dann die über Zeitfunktionen zu definierenden Szenarien für das gesamte Untersuchungs- bzw. Modellgebiet.
Insbesondere für großräumige Untersuchungen ist es jedoch notwendig, die Zeitfunktionen auch räumlich variabel vorgeben zu können. So setzt die Vegetationsentwicklung im Süden früher als im Norden ein (A) und eine großräumige Umwidmung ganzer Relationsklassen ist für sehr große Gebiete ein eher unwahrscheinliches Szenario.
In Auswertung obiger Überlegungen wurden folgende Anforderungen an die Verwaltung zeitvarianter Daten formuliert:
I. Die Art einer Zeitfunktion soll variabel vorgebbar sein, um verschiedene Arten von innerjährlichen, meist zyklischen und überjährlichen, meist trendbehafteten oder durch Sprungstellen gekennzeichneten Abläufen abbilden zu können.
II. Die Zeitfunktionen sollen an Kennwerte einer über ihre ID referenzierbare Relationsklasse (z.B. Relationstyp Nutzung: Nutzungsklasse Wald) oder unmittelbar an die ID selbst der Relationsklasse gebunden werden können.
III. Zusätzlich zur Bindung einer Zeitfunktion an eine Relations-ID soll optional eine selektive Bindung an zu definierende Raumbezüge (REG, TG, KAS, EFL) über deren IDs möglich sein.
Abbildung 5.6-1 zeigt ein Beispiel für eine Zeitfunktionsdefinition. Hier wird eine Verknüpfung zur Wurzeltiefe der Landnutzung mit der ID 5 in der Landnutzungstabelle (hier Wald) hergestellt. Die Zeitfunktion selbst befindet sich in der Datei wald_y.wt. Die Namenswahl für die Zeitfunktionsdateien ist frei. Allerdings ist es angeraten, über die Namensgebung den Inhalt zu dokumentieren. Empfohlen wird folgende Konvention <Relate_Typ>_<Zeitauflösung (s. Abbildung 5.6-2)>.<Kennwert>. Der Kennwert sollte dem Eintrag für DATZ entsprechen.
Unterstützt wird derzeit die Bindung zeitvariabler Werte auf statische Größen der Landnutzungs-, der Bodenarten- und der Flurabstandstabelle, über die Schlüsselwörter :
- NUTZUNG,
- BODENART oder
- GRUNDWASSERFLURABSTAND.
Innerhalb dieser Tabellen ist die zeitvariable Ersetzung der folgenden, statischen Größen (Zieldatenart DATZ) möglich:
- WT – Wurzeltiefe,
- Gwab – Grundwasserflurabstand [mm],
- Aimp – Versieglungsgrad [Anteil 0 …1],
- Intc – Interzeptionskapazitaet [mm]
- Bed – Bedeckungsgrad [Anteil 0 …1],
- LAI – LAI [mm]
- Beregnung – Beregnung [mm/DT[1]]
und zwar immer genau für einen Landnutzungstyp, eine Bodenart oder eine Grundwasserflurabstandsklasse, der über die zugehörige ID definiert ist. Programmintern wird eine Verknüpfung zwischen der ID in der Zeitfunktionsdefinition und dem dieser ID zugehörigen Eintrag in der gewählten Relate-Tabelle hergestellt.

Abbildung 5.6-1: Zeitreihendefinition – ein Beispiel
5.6.1 Unterstützte Zeitfunktionen
Unterstützt werden äquidistante und nicht äquidistante Zeitfunktionen. Die nicht äquidistanten Zeitfunktionen beschreiben über Stützstellen vorzugebende Verläufe. Zwischen den Stützstellen wird linear interpoliert oder eine Stufenfunktion aufgebaut. Bei der Stufenfunktion gilt ein Wert solange, bis er durch einen neuen ersetzt wird.
Die Zeitfunktionen für Kennwerte von Relateklassen befinden sich im Verzeichnis /zeit.dat/ascii.rel/.
Abbildung 5.6-3 bis Abbildung 5.6-4 zeigen einige Beispiele für Zeitfunktionen.
Jede Zeitfunktion wird über genau eine Datei vorgegeben. Die zweite Spalte beinhaltet die eigentlichen Attributwerte, wobei der Attributbezeichner identisch mit dem Bezeichner der Zieldatenart (DATZ – s. Abbildung 5.6-2) sein muss, die erste Spalte den zeitlichen Bezug. Wie dieser zu interpretieren ist, wird über die Datei ../zeit.dat/describe /relates.sdf vorgegeben (s. Abbildung 5.6-2).
###### Zeitvariable Kennwerte ############################################# Termin termin /* durch "." getrennte Datumszeichenkette */ TerminHM terminhm JAHR y MONAT m TAG d STUNDE h MINUTE min MITTLERE_MONATSWERTE mm /* Monatsnummer (1...12) */ MITTELWERT mit MITTLERER_JAHRESGANG TN /* Tagesnummer innerhalb eines Jahres (1...365)*/ +++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++ ###############################################################################
Abbildung 5.6-2: Steuerdatei ../zeit.dat/describe /relates.sdf
Abbildung 5.6-3 und Abbildung 5.6-4 zeigen Dateien, mit denen Jahresgänge über Stützstellen vorgegeben werden können. Zwischen den Stützstellen wird linear interpoliert.
Die erste Datei beinhaltet einen mittleren Jahresgang, der sich zyklisch für jedes Jahr innerhalb des Berechnungszeitraumes wiederholt. Der zeitliche Bezug wird über die Tagesnummer TN hergestellt.

Abbildung 5.6-3: Zeitvariable Kennwerte – mittlerer Jahresgang
Die zweite Datei beinhaltet ein Beispiel zur Vorgabe von Stützstellen zur Beschreibung des Jahresganges für jedes Einzeljahr innerhalb des Simulationszeitraumes. Der zeitliche Bezug ist hier über die komplette Datumsangabe Termin gegeben.

Abbildung 5.6-4: Zeitvariable Kennwerte – Jahresgänge über Stützstellen
Die Beispiele in den folgenden drei Abbildungen beinhalten Stufenfunktionen.
Abbildung 5.6-5 zeigt die Vorgabe eines Jahresganges über mittlere Monatswerte. Diese gelten jeweils genau für den angegebenen Monat, d.h. es müssen genau 12 Werte für die Monatsnummern 1 bis 12 vorgegeben werden.

Abbildung 5.6-5: Zeitvariable Kennwerte – mittlere Monatswerte (Jahresgang)
In Abbildung 5.6-6 und Abbildung 5.6-7 sind Dateien dargestellt, die Monats- bzw. Jahreswerte beinhalten. Jeder Wert gilt vom 1. Tag des angegebenen Monats bzw. Jahres unverändert bis zum 1. Tag des nächsten Eintrages. Damit können Stufenfunktionen mit einer äquidistanten Zeitdiskretisierungen in ein bis n Monate oder Jahre, aber auch nicht äquidistanten Zeitdiskretisierungen definiert werden.

Abbildung 5.6-6: Zeitvariable Kennwerte – Monatswerte

Abbildung 5.6-7: Zeitvariable Kennwerte – Jahreswerte
[1] DT als zeitliche Auflösung der Berechnung, nicht der Daten in der Zeitdatentabelle